Qwen3-Omni Explained: E2E Multimodal, Real-time Speech/Video, 119 Languages (Tech Details + How-to)
This post walks through how to get started with and understand Qwen3-Omni — an end-to-end multilingual, omni-modal model. It handles text, images, audio, and video, and responds in real time with text or natural speech.
Short on time? Jump to “Hands-on Quickstart” to run examples. For the rationale and design choices, see “Technical Details”.
Overview
Introduction
Qwen3-Omni is an end-to-end multilingual, omni-modal foundation model. It supports text, image, audio, and video inputs, and provides streaming responses in text or natural speech. Key highlights:
-
Strong cross-modal performance: Early text-first pretraining + mixed multimodal training; audio/audio-video are strong without sacrificing text/image. Across 36 audio/AV benchmarks, it achieves 22 overall SOTA and 32 open-source SOTA. ASR, audio understanding, and voice conversation are comparable to Gemini 2.5 Pro.
-
Multilingual coverage: 119 text languages, 19 speech input languages, 10 speech output languages.
- Speech input: English, Chinese, Korean, Japanese, German, Russian, Italian, French, Spanish, Portuguese, Malay, Dutch, Indonesian, Turkish, Vietnamese, Cantonese, Arabic, Urdu.
- Speech output: English, Chinese, French, German, Russian, Italian, Spanish, Portuguese, Japanese, Korean.
-
Architecture: Thinker–Talker with MoE, AuT pretraining for strong representations, and multi-codebook to further reduce latency.
-
Real-time interaction: Low-latency streaming for natural turn-taking; instant responses in text or speech.
-
Controllability: System prompts allow fine-grained behavior control.
-
Detailed audio captioning: Qwen3-Omni-30B-A3B-Captioner is open-sourced—general-purpose, highly detailed, low-hallucination audio captioning.
Technical Details (based on arXiv:2509.17765)
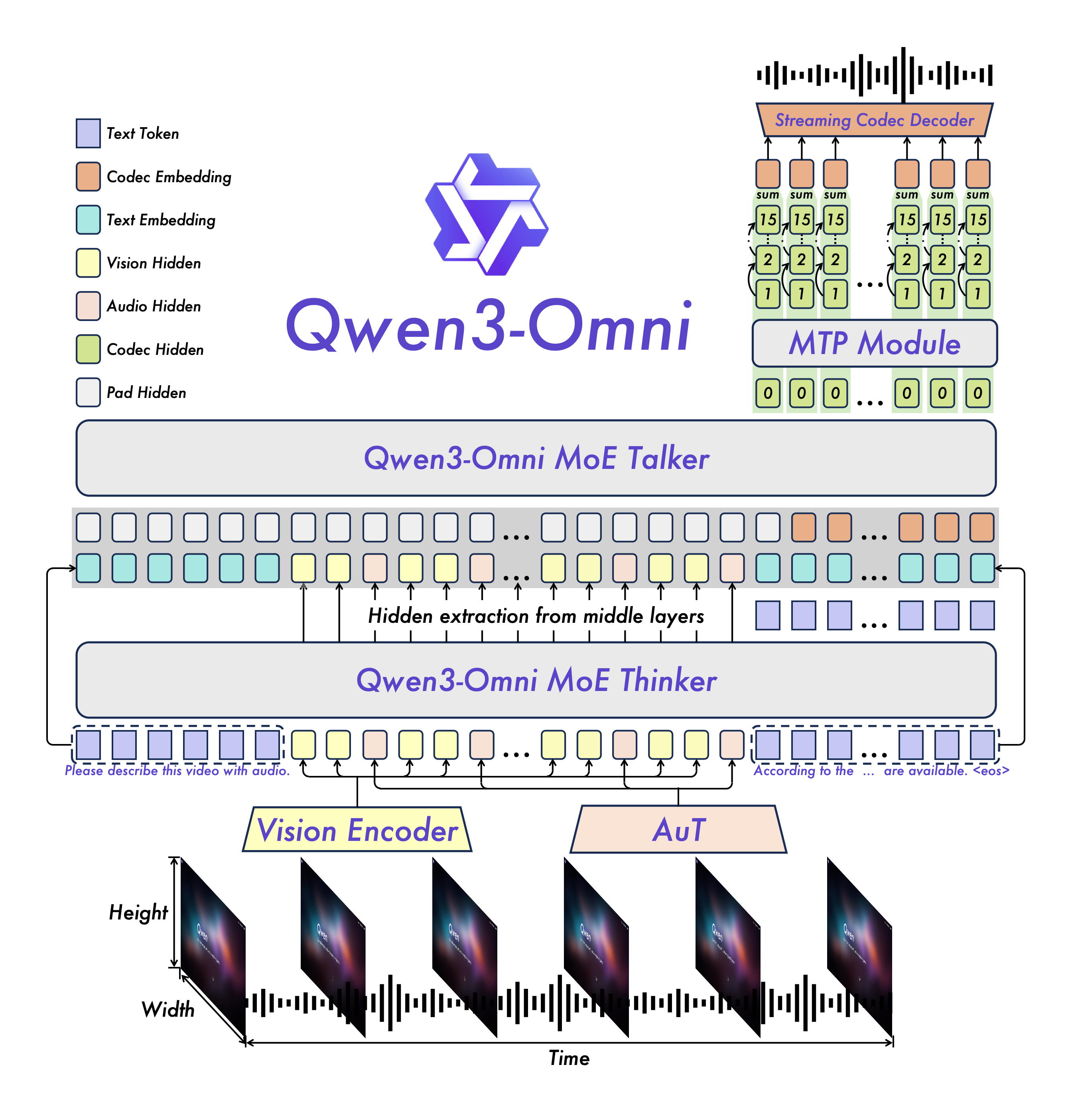
How Thinker–Talker works together
- One end-to-end multimodal backbone: understand + generate for text/image/audio/video in one model, avoiding multi-stage pipelines.
- Thinker (reasoning): cross-modal understanding and reasoning; switch between “thinking” and “non-thinking” modes by task complexity.
- Talker (speaking): real-time text/voice generation; decoupled from Thinker to reduce end-to-end latency and improve controllability.
- MoE + multi-codebook: balances representation power and throughput for both complex tasks and large-scale inference.
Speech synthesis and latency
- Multi-codebook discrete speech: Talker autoregressively predicts codec codebooks for rich representation.
- Replace block-wise diffusion with a lightweight causal ConvNet: more efficient inference; streaming starts from the first codec frame.
- Cold-start end-to-end first-packet latency ~234 ms: sufficient for real-time conversations; even lower perceived latency in ongoing sessions.
- Keep settings consistent across turns: options like
use_audio_in_videomust stay consistent to avoid cache/alignment issues.
Multilingual and multimodal coverage
- Text interaction: 119 languages.
- Speech understanding: 19 languages (incl. Zh/En/Ja/Ko/De/Ru, Cantonese, Arabic, etc.).
- Speech generation: 10 languages (Zh/En/Fr/De/Ru/It/Es/Pt/Ja/Ko).
- Audio/AV is strong while text/image remains on par with single-modal counterparts.
Evaluation: what and how
- 36 audio/AV benchmarks: 32 open-source SOTA, 22 overall SOTA.
- Competitive with Gemini 2.5 Pro on ASR/audio understanding/voice dialogue; surpasses Seed-ASR and GPT-4o-Transcribe on multiple public benchmarks.
- Key recipe: text-first pretraining + mixed multimodal training to stabilize fusion without degrading fundamentals.
Model lineup and licensing
- Instruct: Thinker + Talker, all-rounder; inputs audio/video/text; outputs audio/text.
- Thinking: Thinker only; chain-of-thought reasoning; inputs audio/video/text; outputs text.
- Captioner: audio fine-grained captioning, detailed and low-hallucination; downstream from Instruct.
- License: All three are Apache 2.0 — dev and commercial friendly.
Deployment tips (performance/stability)
- Backend: prefer vLLM (low latency, high throughput); Transformers is great for research/customization. Mind speed/memory for MoE.
- FlashAttention 2: recommended for Transformers (needs compatible hardware; load in fp16/bf16). vLLM bundles FA2 already.
- Tooling: ensure
ffmpegis installed;qwen-omni-utilshelps handle Base64/URL/interleaved multimodal inputs. - Real-time: check I/O and codec settings; the causal ConvNet + multi-codebook path stabilizes streaming.
References & Resources
- arXiv: Qwen3-Omni Technical Report (arXiv:2509.17765)
- PDF: https://github.com/QwenLM/Qwen3-Omni/blob/main/assets/Qwen3_Omni.pdf
- Code & examples: https://github.com/QwenLM/Qwen3-Omni
- Online demos: Hugging Face / ModelScope; real-time voice/video via Qwen Chat.
Architecture
Hands-on Quickstart
Models & Downloads
| Model | Description |
|---|---|
| Qwen3-Omni-30B-A3B-Instruct | Thinker + Talker; input audio/video/text; output audio/text; general interaction. |
| Qwen3-Omni-30B-A3B-Thinking | Thinker only; chain-of-thought reasoning; input audio/video/text; output text. |
| Qwen3-Omni-30B-A3B-Captioner | Fine-grained audio captioning; low hallucination; downstream from Instruct. |
Manual downloads (if online fetching is restricted):
# ModelScope (recommended in Mainland China)
pip install -U modelscope
modelscope download --model Qwen/Qwen3-Omni-30B-A3B-Instruct --local_dir ./Qwen3-Omni-30B-A3B-Instruct
modelscope download --model Qwen/Qwen3-Omni-30B-A3B-Thinking --local_dir ./Qwen3-Omni-30B-A3B-Thinking
modelscope download --model Qwen/Qwen3-Omni-30B-A3B-Captioner --local_dir ./Qwen3-Omni-30B-A3B-Captioner
# Hugging Face CLI
pip install -U "huggingface_hub[cli]"
huggingface-cli download Qwen/Qwen3-Omni-30B-A3B-Instruct --local-dir ./Qwen3-Omni-30B-A3B-Instruct
huggingface-cli download Qwen/Qwen3-Omni-30B-A3B-Thinking --local-dir ./Qwen3-Omni-30B-A3B-Thinking
huggingface-cli download Qwen/Qwen3-Omni-30B-A3B-Captioner --local-dir ./Qwen3-Omni-30B-A3B-CaptionerTransformers install & usage
Tip: use a fresh environment or the official Docker to avoid dependency issues.
# If transformers is installed, consider uninstalling or use a new env
# pip uninstall transformers
pip install git+https://github.com/huggingface/transformers
pip install accelerate
# Multimodal utilities (base64/URL/interleaved audio/images/videos)
pip install qwen-omni-utils -U
# Optional: FlashAttention 2 (reduces memory for Transformers; vLLM already bundles FA2)
pip install -U flash-attn --no-build-isolationHardware must support FlashAttention 2 (load models in fp16/bf16). Check the official docs for compatibility.
Example (multimodal input; text/speech output):
import soundfile as sf
from transformers import Qwen3OmniMoeForConditionalGeneration, Qwen3OmniMoeProcessor
from qwen_omni_utils import process_mm_info
MODEL_PATH = "Qwen/Qwen3-Omni-30B-A3B-Instruct"
# MODEL_PATH = "Qwen/Qwen3-Omni-30B-A3B-Thinking"
model = Qwen3OmniMoeForConditionalGeneration.from_pretrained(
MODEL_PATH,
dtype="auto",
device_map="auto",
attn_implementation="flash_attention_2",
)
processor = Qwen3OmniMoeProcessor.from_pretrained(MODEL_PATH)
conversation = [
{
"role": "user",
"content": [
{"type": "image", "image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-Omni/demo/cars.jpg"},
{"type": "audio", "audio": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-Omni/demo/cough.wav"},
{"type": "text", "text": "What do you see and hear? Answer in one sentence."}
],
},
]
USE_AUDIO_IN_VIDEO = True
text = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)
audios, images, videos = process_mm_info(conversation, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = processor(
text=text,
audio=audios,
images=images,
videos=videos,
return_tensors="pt",
padding=True,
use_audio_in_video=USE_AUDIO_IN_VIDEO,
)
inputs = inputs.to(model.device).to(model.dtype)
text_ids, audio = model.generate(
**inputs,
speaker="Ethan",
thinker_return_dict_in_generate=True,
use_audio_in_video=USE_AUDIO_IN_VIDEO,
)
text = processor.batch_decode(
text_ids.sequences[:, inputs["input_ids"].shape[1] :],
skip_special_tokens=True,
clean_up_tokenization_spaces=False,
)
print(text)
if audio is not None:
sf.write(
"output.wav",
audio.reshape(-1).detach().cpu().numpy(),
samplerate=24000,
)vLLM usage notes
text = processor.apply_chat_template(messages, add_generation_prompt=True, tokenize=False)
inputs = {
"prompt": text,
"multi_modal_data": {},
"mm_processor_kwargs": {
"use_audio_in_video": True,
},
}Keep use_audio_in_video consistent across multi-turn conversations to avoid cache misalignment.
Local Web UI Demo
Install deps:
pip install gradio==5.44.1 gradio_client==1.12.1 soundfile==0.13.1Run examples:
# Instruct (vLLM backend)
python web_demo.py -c Qwen/Qwen3-Omni-30B-A3B-Instruct
# Instruct (Transformers backend, with speech generation)
python web_demo.py -c Qwen/Qwen3-Omni-30B-A3B-Instruct --use-transformers --generate-audio
# Instruct (Transformers + FlashAttention 2)
python web_demo.py -c Qwen/Qwen3-Omni-30B-A3B-Instruct --use-transformers --generate-audio --flash-attn2# Thinking (vLLM backend)
python web_demo.py -c Qwen/Qwen3-Omni-30B-A3B-Thinking
# Thinking (Transformers backend)
python web_demo.py -c Qwen/Qwen3-Omni-30B-A3B-Thinking --use-transformers
# Thinking (Transformers + FlashAttention 2)
python web_demo.py -c Qwen/Qwen3-Omni-30B-A3B-Thinking --use-transformers --flash-attn2# Captioner (vLLM backend)
python web_demo_captioner.py -c Qwen/Qwen3-Omni-30B-A3B-Captioner
# Captioner (Transformers backend)
python web_demo_captioner.py -c Qwen/Qwen3-Omni-30B-A3B-Captioner --use-transformersMore Articles
![OpenAI 12-Day Technical Livestream Highlights Detailed Report [December 2024]](/_astro/openai-12day.C2KzT-7l_1ndTgg.jpg)







