DeepSeek-V3 Model In-Depth Analysis: A Brilliant Star in the New AI Era

In today’s rapidly evolving artificial intelligence landscape, the DeepSeek-V3 model shines like a brilliant new star, illuminating the path forward in the field of language models. Let’s delve deep into its unique charm and value.
I. Architectural Design - The Fusion of Intelligence and Efficiency
DeepSeek-V3’s adoption of Multi-head Latent Attention (MLA) and DeepSeekMoE architecture undoubtedly forms the cornerstone of its powerful performance. This innovative architectural design, through clever load balancing strategies, flexibly activates corresponding expert modules based on the specific context of input text. This process is akin to an experienced expert who can quickly tap into the most proficient knowledge domain to answer different questions, requiring only 37 billion parameters yet demonstrating capabilities surpassing traditional models. In practical applications, whether handling complex text generation tasks or scenarios requiring precise understanding and answers, it can quickly and accurately deliver high-quality results, providing users with a smooth and efficient experience, fully demonstrating the ingenuity of its architectural design - a perfect example of the fusion of intelligence and efficiency.
II. Training Process - A Meticulously Crafted Journey of Growth
-
Data Foundation: The 14.8 trillion high-quality tokens used in its pre-training serve as a treasure trove of knowledge, extensively covering rich information across various fields. This data provides comprehensive and balanced nutrition for the model, enabling it to build a solid foundation in all aspects of language understanding and generation, thus demonstrating deep knowledge reserves and broad applicability when facing diverse tasks.
-
Framework Support: Based on the internally crafted HAI-LLM framework, through advanced technologies such as 16-way pipeline parallelism, 64-way expert parallelism, and ZeRO-1 data parallelism, combined with optimization methods like the DualPipe algorithm, a high-speed channel for model training was established. This enables the model to fully utilize computational resources during training, efficiently absorb and integrate knowledge, and rapidly improve its capabilities, ensuring each parameter update moves towards optimization, like an athlete steadily improving under professional coaching.
-
Technical Refinement: The innovative FP8 mixed-precision training framework and fine-grained quantization strategies are like careful polishing of every aspect of the model training process. These technologies not only reduce GPU memory pressure, making the training process more stable and efficient, but also achieve significant optimization in training costs. Throughout the long training process, there were no troublesome loss spikes or rollbacks, ensuring the model could continuously and steadily progress toward higher performance levels, demonstrating excellent training stability and sustainable development.
III. Innovative Technology - Breaking Through Traditional Boundaries
-
Multi-Token Prediction (MTP): The establishment of the MTP training objective is undoubtedly a powerful tool in DeepSeek-V3’s arsenal, breaking free from traditional training mode constraints. By sequentially predicting additional tokens through multiple modules while maintaining complete causal chains, this innovative measure greatly enhances the model’s text understanding and generation capabilities. In practical applications, whether writing logically rigorous academic papers or generating creative and coherent stories, MTP technology enables the model to produce more fluent, natural, and logical outputs, providing users with higher quality, coherent text content, demonstrating language mastery capabilities beyond traditional models.
-
Supervised Fine-tuning and Reinforcement Learning: Through the careful refinement of supervised fine-tuning and reinforcement learning stages, DeepSeek-V3 fully unleashed its potential, achieving a magnificent transformation from “novice” to “expert.” The datasets used in the supervised fine-tuning stage, covering multiple domains, provide the model with rich and diverse practical scenarios, enabling it to learn precise response strategies for problems across different fields. The rules and model-based reward models and group relative policy optimization employed in the reinforcement learning stage act like a strict and wise mentor, continuously guiding the model to optimize its response strategies through user interactions, improving the accuracy, rationality, and satisfaction of responses, thus performing excellently in various complex practical application scenarios, providing users with more intelligent and attentive service experiences.
IV. Performance - Achievements Forged by Capability
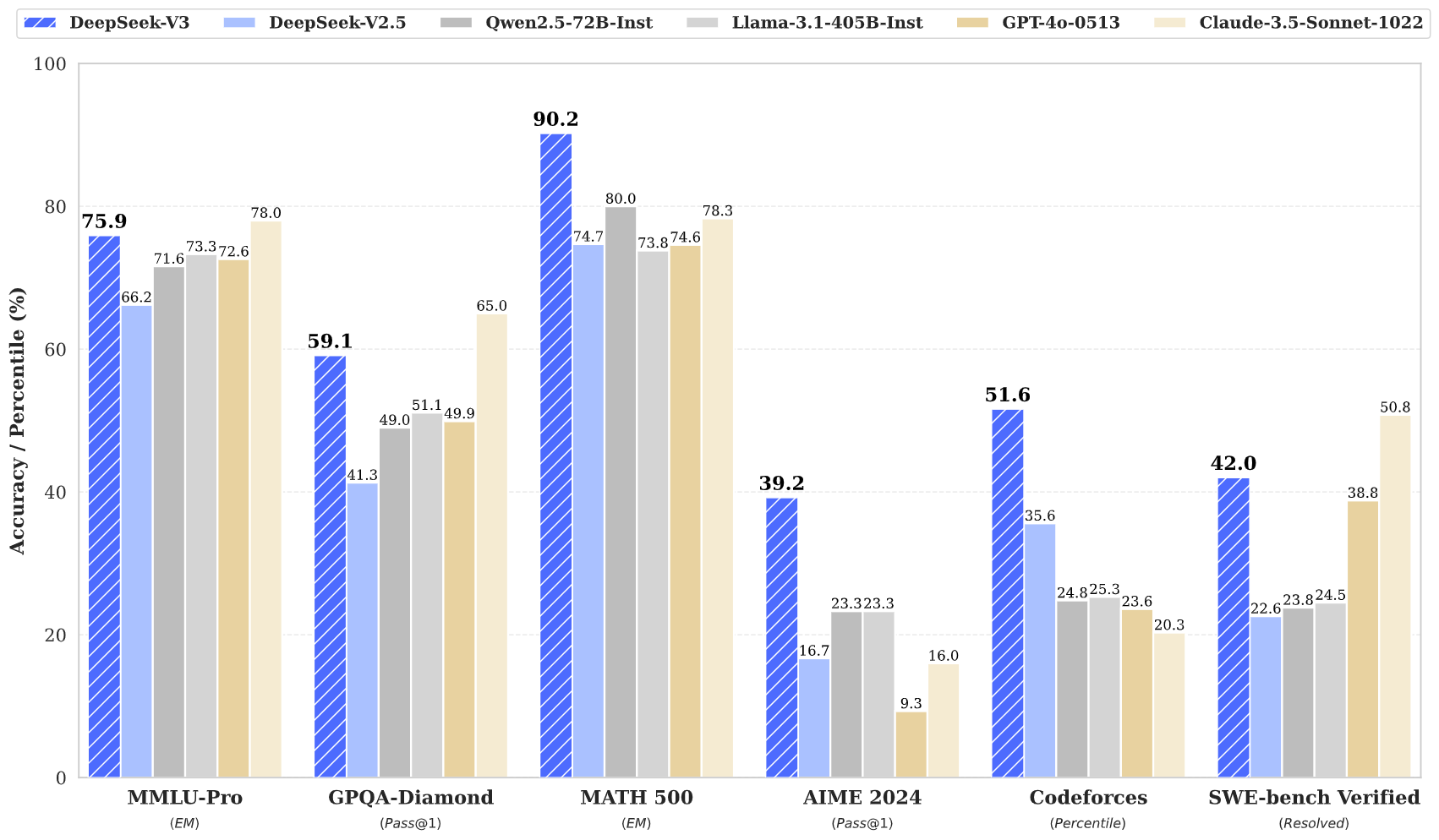
-
Pre-training Evaluation: In fierce competition with numerous open-source models, DeepSeek-V3 stands out in multiple benchmark tests, demonstrating exceptional capabilities. Particularly in mathematics and coding tasks, its excellent performance in tests such as Math500, AIME2024, and Codeforces fully proves its strong logical reasoning and programming thinking abilities. This enables it to provide accurate and efficient solutions when handling practical tasks related to mathematical calculations and programming, whether solving complex mathematical problems or writing high-quality code snippets, offering powerful support tools for professionals and learners in related fields.
-
Post-training Evaluation: Its chat version’s outstanding performance in various standard and open-ended benchmark tests is particularly noteworthy. Not only does it excel in comparison with other open-source models, but it also holds its own against closed-source models like GPT-4o and Claude-3.5-Sonnet, showing unique advantages especially in Chinese factual knowledge. This means that in daily chat interactions and knowledge Q&A scenarios, DeepSeek-V3 can provide accurate, detailed answers that conform to Chinese language habits and cultural background, greatly enhancing user experience in information acquisition and communication interaction, whether answering professional knowledge questions or engaging in casual conversation, meeting user needs and serving as a reliable intelligent companion.
V. Cost-effectiveness - A Wise Choice with High Value for Money
While pursuing excellent performance, DeepSeek-V3 hasn’t overlooked the key factor of cost-effectiveness. Its training cost is only 2.788m H800 GPU hours, costing $5.576 million, which shows a significant advantage compared to the high training costs of models like Llama3-405B. This enables more research institutions and enterprises to adopt this advanced model within limited budgets, promoting the application and development of AI technology across broader fields. Moreover, its API pricing is highly attractive, with input prices at just 1/20th and output prices at 1/30th of GPT-4o’s rates. For developers and enterprise users, this means they can access high-quality language model services at lower costs when developing applications and deploying DeepSeek-V3, thus gaining a more advantageous position in market competition. Whether developing intelligent customer service systems, content generation platforms, or intelligent writing assistance applications, they can minimize operational costs while maintaining performance, maximizing economic benefits - truly a wise choice with high cost-effectiveness.
The DeepSeek-V3 model has become an outstanding representative in the current language model field through its excellent advantages in architectural design, training process, innovative technology, performance, and cost-effectiveness. It not only injects new vitality into the development of artificial intelligence technology but also brings more intelligent, efficient, and economical solutions to users and developers. Taking a solid and powerful step on the road to promoting the popularization and application of artificial intelligence technology, it is expected to play an increasingly important role in the future intelligent era, leading language model technology toward new glory.
related links
More Articles
![OpenAI 12-Day Technical Livestream Highlights Detailed Report [December 2024]](/_astro/openai-12day.C2KzT-7l_1ndTgg.jpg)







