MinerU 完全入门指南 - PDF文档数据提取的开源利器
8 min read
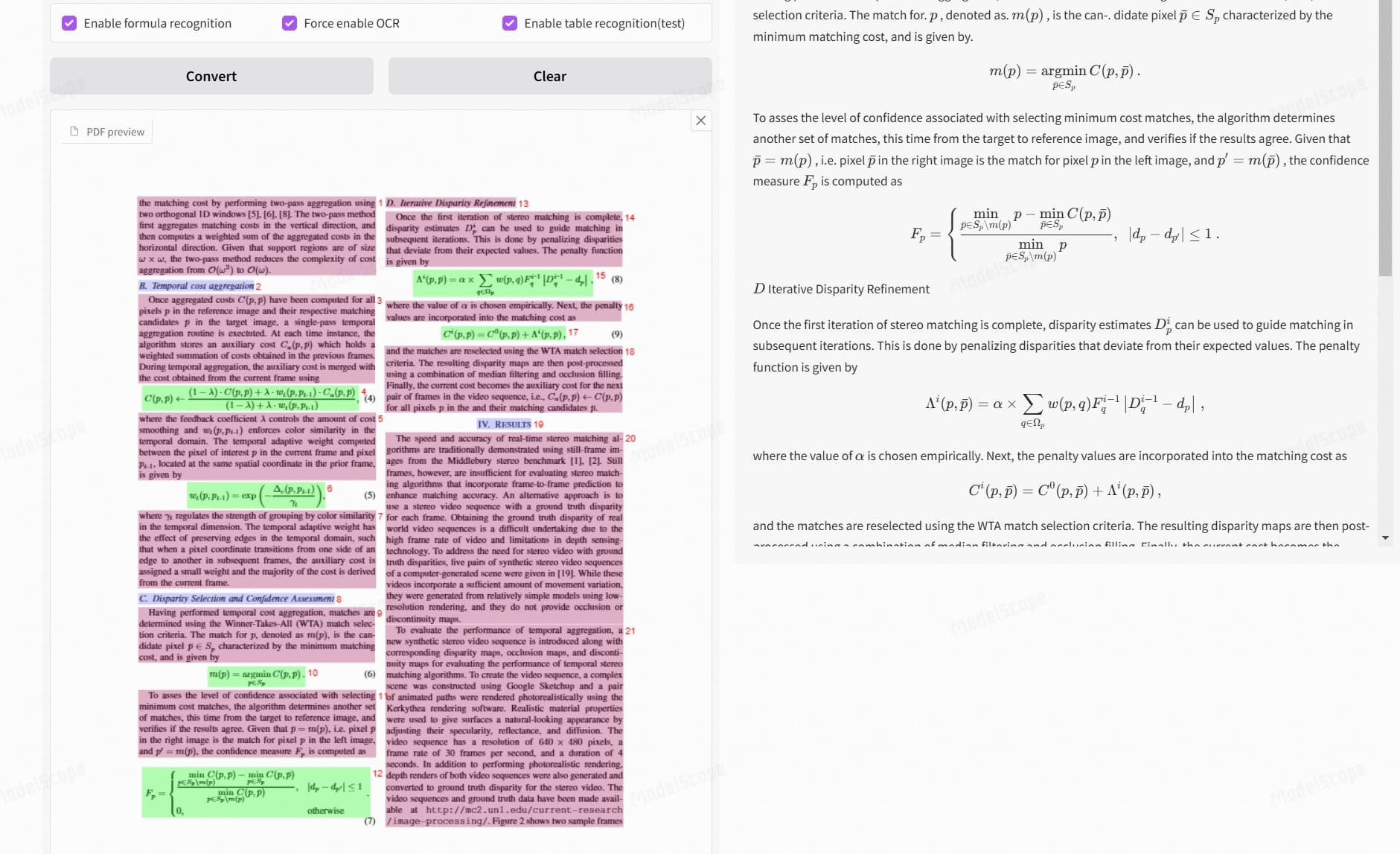
MinerU是什么?
MinerU是一款强大的开源PDF数据提取工具,由OpenDataLab开发。它能够智能地将PDF文档转换为结构化的数据格式,支持文本、图片、表格和数学公式的精确提取。无论是处理学术论文、技术文档还是商业报告,MinerU都能帮你轻松应对。
核心特性
- 🚀 智能清理 - 自动移除页眉页脚等干扰内容
- 📝 结构保持 - 完整保留原文档的层级结构
- 🖼️ 多模态支持 - 精确提取图片、表格及说明文字
- ➗ 公式转换 - 自动识别数学公式并转为LaTeX
- 🌍 多语言OCR - 支持84种语言的文字识别
- 💻 跨平台兼容 - 支持所有主流操作系统
多语言支持
MinerU基于PaddleOCR提供强大的多语言识别能力,支持80+种语言:
主要语种支持
| 语种 | 缩写 | 描述 | 语种 | 缩写 | 描述 |
|---|---|---|---|---|---|
| 中文 | ch | 中英文混合 | 英文 | en | 英语 |
| 日文 | japan | 日语 | 韩文 | korean | 韩语 |
| 俄语 | ru | 俄罗斯语 | 法语 | fr | 法语 |
| 德语 | german | 德语 | 意大利语 | it | 意大利语 |
| 西班牙语 | es | 西班牙语 | 葡萄牙语 | pt | 葡萄牙语 |
特色语种支持
| 语系 | 语种 | 缩写 |
|---|---|---|
| 亚洲语系 | 繁体中文 | chinese_cht |
| 亚洲语系 | 维吾尔语 | ug |
| 亚洲语系 | 泰米尔语 | ta |
| 亚洲语系 | 泰卢固语 | te |
| 亚洲语系 | 尼泊尔语 | ne |
| 欧洲语系 | 塞尔维亚语 | latin/cyrillic |
| 欧洲语系 | 克罗地亚语 | hr |
| 欧洲语系 | 爱尔兰语 | ga |
| 欧洲语系 | 匈牙利语 | hu |
| 中东语系 | 阿拉伯语 | ar |
| 中东语系 | 波斯语 | fa |
| 中东语系 | 乌尔都语 | ur |
| 中东语系 | 库尔德语 | ku |
使用方法
在处理文档时,可以通过指定语言参数来优化识别效果:
magic-pdf -p paper.pdf -o output -m auto --lang ch提示:选择正确的语言可以显著提高识别准确率。对于混合语言文档,建议使用自动检测模式。
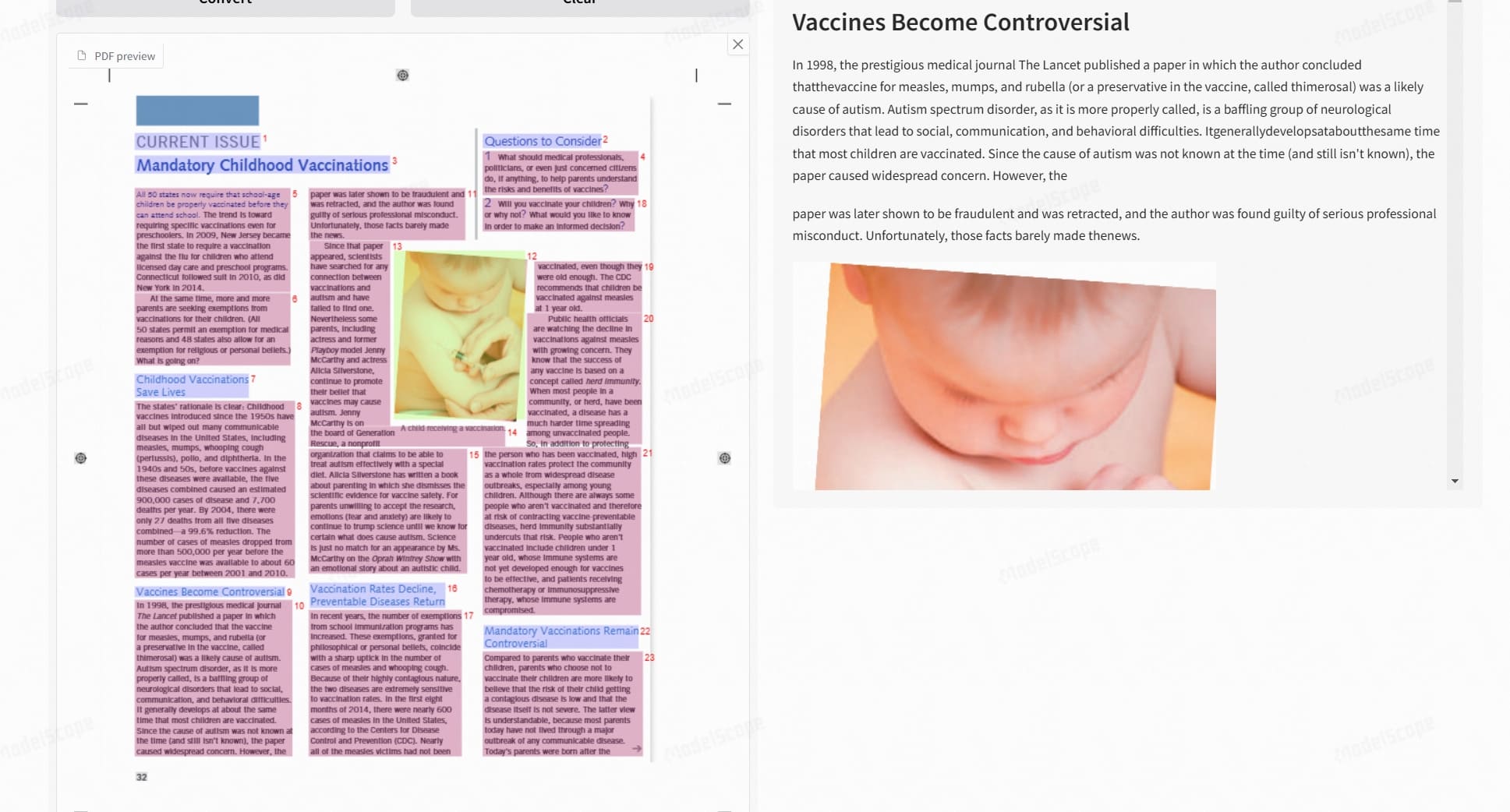
效果展示
快速开始
在线体验
不想安装?直接访问以下平台即可体验:
- HuggingFace空间 - 测试版
- ModelScope - 测试版
本地安装
基础环境配置
# 创建虚拟环境
conda create -n MinerU python=3.10
conda activate MinerU
# 安装核心包
pip install -U magic-pdf[full] --extra-index-url https://wheels.myhloli.com基本使用方法
# 处理单个文件
magic-pdf -p paper.pdf -o output -m auto
# 批量处理文件夹
magic-pdf -p papers_dir -o output -m auto进阶功能
GPU加速配置
如果您的显卡显存大于等于8GB,可以按照以下步骤启用CUDA加速:
1. 修改配置文件
找到用户目录下的magic-pdf.json文件,修改”device-mode”的值:
{
"device-mode": "cuda"
}2. 启用CUDA加速
运行以下命令测试CUDA加速效果:
magic-pdf -p small_ocr.pdf -o ./output提示: CUDA加速是否生效可以根据log中输出的各个阶段cost耗时来判断。通常情况下,
layout detection cost和mfr time应提速10倍以上。
3. OCR加速配置
为了让OCR也支持CUDA加速,需要安装paddlepaddle-gpu:
# 安装paddlepaddle-gpu,完成后会自动开启ocr加速
python -m pip install paddlepaddle-gpu==3.0.0b1 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/
# 测试ocr加速效果
magic-pdf -p small_ocr.pdf -o ./output提示: OCR加速生效后,log中的
ocr cost耗时应该减少10倍以上。
表格识别增强
最新版本集成了RapidTable表格识别引擎:
- ⚡ 识别速度提升10倍
- 🎯 更高的识别准确率
- 💾 更低的资源占用
API集成开发
MinerU提供了灵活的Python API,以下是一个完整的使用示例:
import os
from loguru import logger
from magic_pdf.pipe.UNIPipe import UNIPipe
from magic_pdf.pipe.OCRPipe import OCRPipe
from magic_pdf.pipe.TXTPipe import TXTPipe
from magic_pdf.rw.DiskReaderWriter import DiskReaderWriter
def pdf_parse_main(
pdf_path: str,
parse_method: str = 'auto',
model_json_path: str = None,
is_json_md_dump: bool = True,
output_dir: str = None
):
"""
执行从pdf转换到json、md的过程
:param pdf_path: .pdf文件的路径
:param parse_method: 解析方法,支持auto、ocr、txt三种,默认auto
:param model_json_path: 已存在的模型数据文件路径
:param is_json_md_dump: 是否保存解析数据到json和md文件
:param output_dir: 输出目录路径
"""
try:
# 准备输出路径
pdf_name = os.path.basename(pdf_path).split(".")[0]
if output_dir:
output_path = os.path.join(output_dir, pdf_name)
else:
pdf_path_parent = os.path.dirname(pdf_path)
output_path = os.path.join(pdf_path_parent, pdf_name)
output_image_path = os.path.join(output_path, 'images')
image_path_parent = os.path.basename(output_image_path)
# 读取PDF文件
pdf_bytes = open(pdf_path, "rb").read()
# 初始化writer
image_writer = DiskReaderWriter(output_image_path)
md_writer = DiskReaderWriter(output_path)
# 选择解析方式
if parse_method == "auto":
jso_useful_key = {"_pdf_type": "", "model_list": []}
pipe = UNIPipe(pdf_bytes, jso_useful_key, image_writer)
elif parse_method == "txt":
pipe = TXTPipe(pdf_bytes, [], image_writer)
elif parse_method == "ocr":
pipe = OCRPipe(pdf_bytes, [], image_writer)
else:
logger.error("unknown parse method, only auto, ocr, txt allowed")
return
# 执行处理流程
pipe.pipe_classify() # 文档分类
pipe.pipe_analyze() # 文档分析
pipe.pipe_parse() # 内容解析
# 生成输出内容
content_list = pipe.pipe_mk_uni_format(image_path_parent)
md_content = pipe.pipe_mk_markdown(image_path_parent)
# 保存结果
if is_json_md_dump:
# 保存模型结果
md_writer.write(
content=json.dumps(pipe.model_list, ensure_ascii=False, indent=4),
path=f"{pdf_name}_model.json"
)
# 保存内容列表
md_writer.write(
content=json.dumps(content_list, ensure_ascii=False, indent=4),
path=f"{pdf_name}_content_list.json"
)
# 保存Markdown
md_writer.write(
content=md_content,
path=f"{pdf_name}.md"
)
except Exception as e:
logger.exception(e)
# 使用示例
if __name__ == '__main__':
pdf_path = "demo.pdf"
pdf_parse_main(
pdf_path=pdf_path,
parse_method="auto",
output_dir="./output"
)提示: 上述代码展示了完整的处理流程,包括:
- 支持多种解析方式(auto/ocr/txt)
- 自动创建输出目录结构
- 保存模型结果、内容列表和Markdown输出
- 异常处理和日志记录
实战应用场景
1. 学术研究
- 批量提取研究论文数据
- 构建文献知识库
- 提取实验数据和图表
2. 数据分析
- 提取财务报表数据
- 处理技术文档
- 分析研究报告
3. 内容管理
- 文档数字化转换
- 建立搜索系统
- 知识库构建
4. 开发集成
- RAG系统开发
- 文档处理服务
- 内容分析平台
性能优化建议
- 内存管理
- 批量处理时控制并发数
- 及时清理临时文件
- 使用生成器处理大文件
- GPU使用
- 选择合适的batch size
- 监控显存使用情况
- 根据需求调整模型精度
- 输出优化
- 选择合适的输出格式
- 压缩图片节省空间
- 使用增量保存避免数据丢失
常见问题解决
1. 安装问题
Q: 安装时报错”未找到预编译包”? A: 检查Python版本是否为3.10,并确保pip源配置正确。
2. 识别问题
Q: 复杂公式识别不准确? A: 尝试使用高精度模式,并确保PDF质量良好。
3. 性能问题
Q: 处理大文件很慢? A: 启用GPU加速,并适当调整batch size。
更多文章

Qwen3-Next 系列全解析:80B-A3B 的混合架构,Instruct 与 Thinking 双线能力进化

DeepSeek V3.1:混合推理、强劲编程与 Agent 能力,支持Claude Code,性价比再升级

Qwen-Image-Edit 图像编辑介绍与 ComfyUI 使用指南

沉浸式翻译插件重大安全漏洞:网页快照功能导致用户敏感信息大规模泄露

GLM-4.5技术报告与应用体验:国产智能体大模型新标杆

Win11Debloat 深度指南:一键精简 Windows 11,告别臃肿,提升系统性能

阿里Qwen-MT翻译模型重磅升级:92种语言、秒级响应,挑战GPT-4翻译霸主地位

Kimi K2如何凭借三大创新炼成万亿开源模型?
Docker运行macOS教程:Linux系统完整配置与部署指南