Microsoft OmniParser V2.0: Major Upgrade in AI Visual Parsing, Advancing Automation and Accessibility
Microsoft has recently released OmniParser V2.0, a powerful tool capable of converting graphical user interface (GUI) screenshots into structured data. As a major breakthrough in artificial intelligence (AI), OmniParser V2.0 opens new possibilities for automation and accessibility by enhancing the interaction capabilities between large language models (LLMs) and visual elements on screen.
OmniParser V2.0 aims to improve AI efficiency in understanding and manipulating user interfaces. By converting screenshots into structured data, the tool enables AI models to identify, understand, and interact with interface elements, achieving more intelligent and efficient application automation and user assistance functions.
Key Features and Improvements:
-
Significant Speed Boost: OmniParser V2.0 reduces latency by 60% compared to its predecessor, with average processing times of just 0.6 and 0.8 seconds on high-end GPUs (A100 and 4090 models respectively), greatly improving processing efficiency.
-
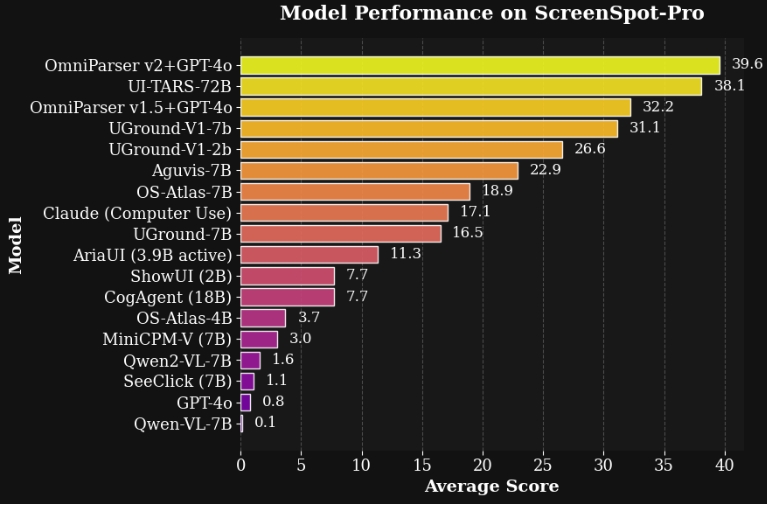
Enhanced Accuracy: In the ScreenSpot Pro benchmark, OmniParser V2.0 achieves an average accuracy of 39.6% in detecting interactive elements, marking a quantum leap from previous versions.
-
Robust Input and Output Capabilities:
- Input: Supports screenshots from multiple platforms including Windows, mobile devices, and web applications.
- Output: Generates structured representations of interactive elements, including clickable area location data and UI component functional descriptions.
-
Seamless LLM Integration: Through the unified OmniTool interface, OmniParser V2.0 integrates with various AI models including OpenAI’s GPT-4o, DeepSeek R1, Qwen 2.5VL, and Anthropic Sonnet, facilitating the creation of automated testing tools and accessibility solutions.
Technical Upgrades:
OmniParser V2.0 employs fine-tuned YOLOv8 models and the Florence-2 foundation model, enhancing its understanding of interface elements. The training dataset has been expanded to include more comprehensive information about icons and their functions, significantly improving the model’s performance in detecting small UI components.
Quick Start
Follow these steps to set up the conda virtual environment and install dependencies:
- Environment Setup
conda create -n "omni" python==3.12
conda activate omni
pip install -r requirements.txt- Download Models
rm -rf weights/icon_detect weights/icon_caption weights/icon_caption_florence
huggingface-cli download microsoft/OmniParser-v2.0 --local-dir weights
mv weights/icon_caption weights/icon_caption_florence- Run Demos
- Using Jupyter Notebook:
Open
demo.ipynbto view example code - Using Web Interface:
python gradio_demo.py
Wide-ranging Applications:
OmniParser V2.0 has broad applications in the following areas:
-
UI Automation: Enables AI agents to interact with GUIs, automating repetitive tasks.
-
Accessibility Solutions: Helps users with disabilities by providing structured data that can be interpreted by assistive technologies.
-
User Interface Analysis: Analyzes and improves user interfaces based on structured data extracted from screenshots.
Microsoft states that the release of OmniParser V2.0 marks a significant milestone in AI visual parsing. With its exceptional speed, accuracy, and integration capabilities, OmniParser V2.0 will become an essential tool for developers and enterprises in AI-driven technical solutions, delivering smarter and more convenient experiences to users. As technology continues to evolve, OmniParser V2.0 is expected to drive more innovative applications and bring far-reaching impact across various industries.
Related Links
More Articles
![OpenAI 12-Day Technical Livestream Highlights Detailed Report [December 2024]](/_astro/openai-12day.C2KzT-7l_1ndTgg.jpg)







