STAR: 基于文本到视频模型的实际场景视频超分辨率技术
4 min read

简介
STAR (Spatial-Temporal Augmentation with Text-to-Video Models) 是一个创新的实际场景视频超分辨率框架,由南京大学、字节跳动、西南大学联合开发。它首次将多样化、强大的文本到视频扩散先验模型整合到实际场景的视频超分辨率中,有效解决了传统方法在处理真实世界视频时面临的诸多挑战。
核心特性
- 🌟 创新的时空质量增强框架:专门针对实际场景的视频超分辨率设计
- 🎯 强大的文本到视频模型集成:利用T2V模型提升视频质量
- 🔄 出色的时间一致性:有效保持视频帧之间的连贯性
- 🖼️ 真实的空间细节:生成高质量、细节丰富的视频画面
- 🛠️ 实用的开源实现:提供完整的代码和预训练模型
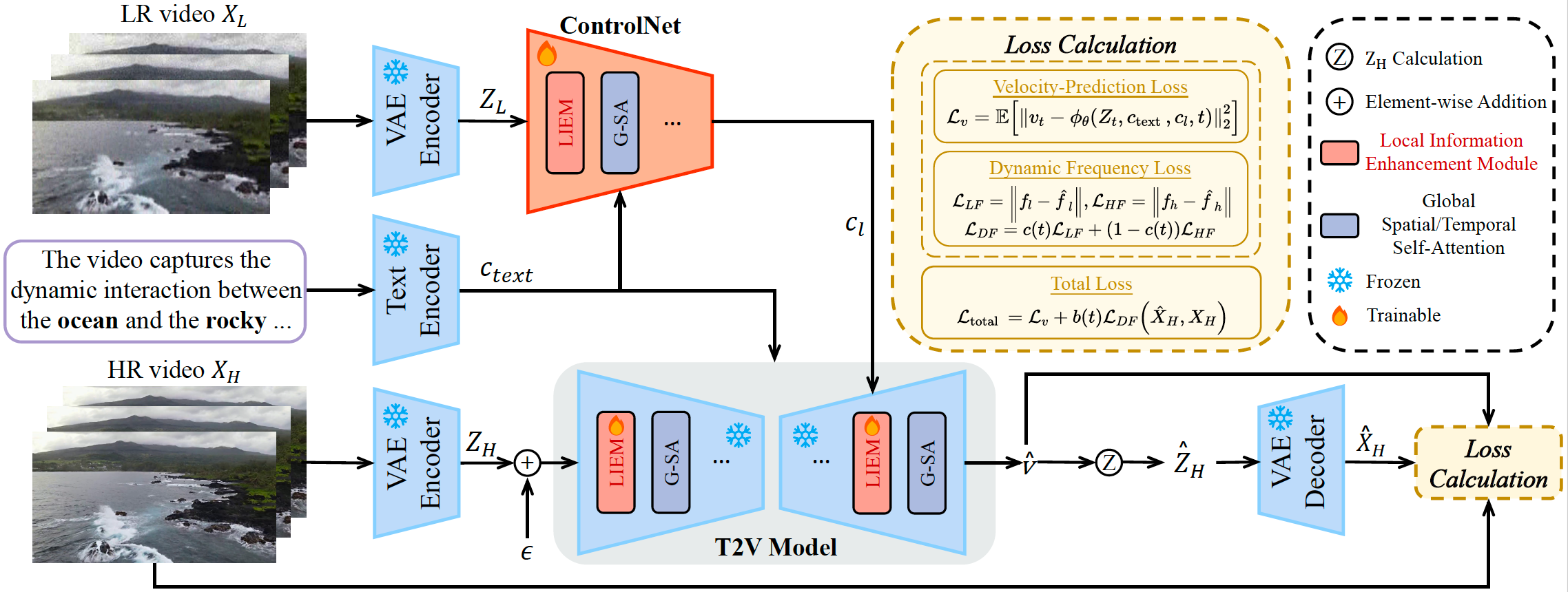
技术原理
STAR框架包含四个主要模块:
- VAE编码器:处理视频输入
- 文本编码器:处理提示文本
- ControlNet:控制生成过程
- T2V模型与局部信息增强模块(LIEM):
- LIEM专门设计用于减少伪影
- 动态频率(DF)损失函数用于自适应调整高频和低频组件的约束
这些组件协同工作,实现了高时空质量、减少伪影和增强保真度的目标。
安装使用
环境配置
# 克隆仓库
git clone https://github.com/NJU-PCALab/STAR.git
cd STAR
# 创建环境
conda create -n star python=3.10
conda activate star
pip install -r requirements.txt
sudo apt-get update && apt-get install ffmpeg libsm6 libxext6 -y预训练模型
STAR提供两种基础模型版本:
-
I2VGen-XL基础版本
- 轻度退化模型:适用于轻微质量损失的视频
- 重度退化模型:适用于严重质量损失的视频
-
CogVideoX-5B基础版本
- 专门用于处理重度退化视频
- 仅支持720x480输入分辨率
使用步骤
-
下载预训练模型
- 从HuggingFace下载模型权重
- 将权重文件放入
pretrained_weight/目录
-
准备测试数据
- 将测试视频放入
input/video/目录 - 文本提示有三个选项:
- 无提示
- 使用Pllava自动生成提示
- 手动编写提示(放入
input/text/)
- 将测试视频放入
-
配置路径 修改
video_super_resolution/scripts/inference_sr.sh中的路径:- video_folder_path
- txt_file_path
- model_path
- save_dir
-
运行推理
bash video_super_resolution/scripts/inference_sr.sh注意:如果遇到内存不足问题,可以在
inference_sr.sh中设置较小的frame_length值。
实际效果
STAR在处理实际场景视频时展现出显著优势:
- 对于从Bilibili等平台下载的低分辨率视频,能有效提升画质
- 在处理重度退化视频时,可以显著改善视觉质量
- 生成的视频保持良好的时间连贯性
- 细节保真度高,不会产生过度平滑的效果
总结
STAR为实际场景的视频超分辨率提供了一个强大的解决方案。通过创新的架构设计和先进的文本到视频模型的整合,它能够有效处理各种实际场景中的视频质量提升需求。项目的开源特性也使得研究者和开发者能够方便地使用和改进这一技术。
更多文章

Qwen3-Next 系列全解析:80B-A3B 的混合架构,Instruct 与 Thinking 双线能力进化

DeepSeek V3.1:混合推理、强劲编程与 Agent 能力,支持Claude Code,性价比再升级

Qwen-Image-Edit 图像编辑介绍与 ComfyUI 使用指南

沉浸式翻译插件重大安全漏洞:网页快照功能导致用户敏感信息大规模泄露

GLM-4.5技术报告与应用体验:国产智能体大模型新标杆

Win11Debloat 深度指南:一键精简 Windows 11,告别臃肿,提升系统性能

阿里Qwen-MT翻译模型重磅升级:92种语言、秒级响应,挑战GPT-4翻译霸主地位

Kimi K2如何凭借三大创新炼成万亿开源模型?
Docker运行macOS教程:Linux系统完整配置与部署指南