【最新】Stable Diffusion 3.5安装教程:ComfyUI平台完整指南

2024年10月22日,StabilityAI正式发布了全新的Stable Diffusion 3.5。这是对此前备受争议的SD3版本的重大升级和改进。本次发布的模型保持开源特性,同时采取了负责任的措施来防止滥用。
Stable Diffusion 3.5三大版本对比
目前SD3.5提供三个不同版本,以满足不同用户需求:
| 模型版本 | 参数规模 | 分辨率支持 | 核心优势 | 最佳应用场景 |
|---|---|---|---|---|
| SD 3.5 Large | 80亿 | 100万像素 | • 最强大的基础模型 • 卓越的图像质量 • 精准的提示词响应 | 专业级高质量创作 |
| SD 3.5 Large Turbo | 80亿 | 100万像素 | • Large版本的优化版 • 仅需4步快速生成 • 保持高质量输出 | 需要快速迭代的项目 |
| SD 3.5 Medium | 25亿 | 25-200万像素 | • 适配普通显卡 • 优化的架构设计 • 更易于定制训练 | 个人创作和小型商用 |
授权与使用说明
- 所有模型权重均可自由定制
- 年收入100万美元以下可免费商用
- 遵循StabilityAI社区许可协议
- 企业用户可查看官方许可页面获取详细信息
本教程将重点介绍如何在ComfyUI平台上安装和使用SD3.5。目前A1111版本尚未支持,ForgeUI团队正在开发中,我们会及时更新教程。
关注 @SD_Tutorial 获取最新更新动态
目录
安装
如果你是新手,你必须在你的机器上安装ComfyUI。老用户需要通过导航到Manager并选择”Update ComfyUI”和”Update All”来更新ComfyUI。我们列出了社区的各种发布版本。你可以根据你的需求和系统配置进行选择。
类型A: StabilityAI的Stable Diffusion 3.5
拥有强大GPU并且只想使用原始模型的用户可以使用这个官方版本。
1. 三种模型变体如下:
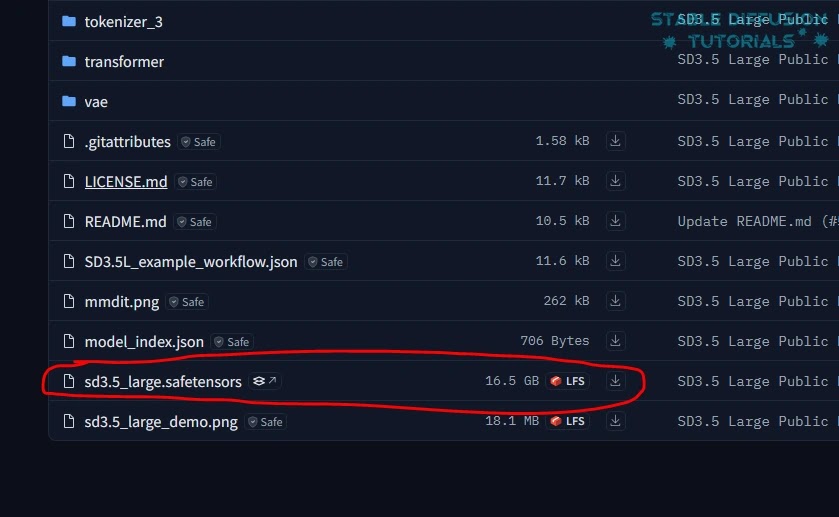
(a) 从StabilityAI的Hugging face下载Stable Diffusion 3.5 Large的模型权重。
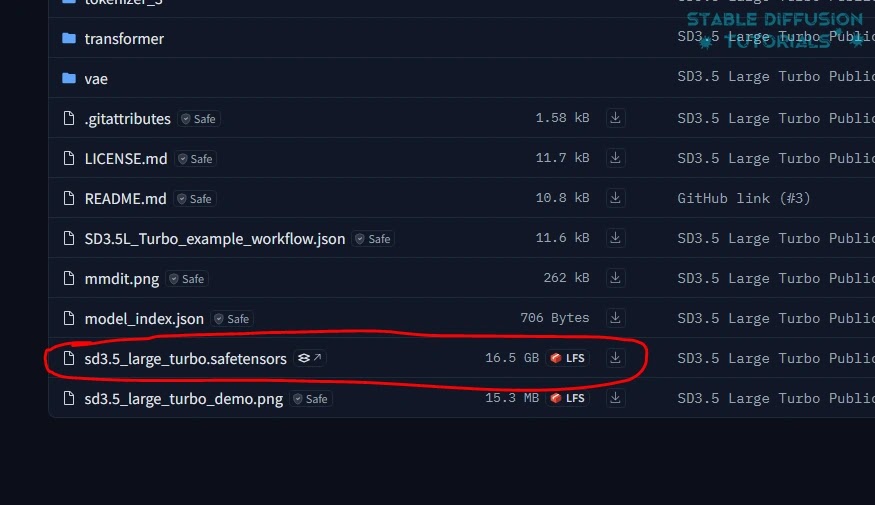
(b) 从StabilityAI的Hugging face下载Stable Diffusion 3.5 Large Turbo的模型权重。
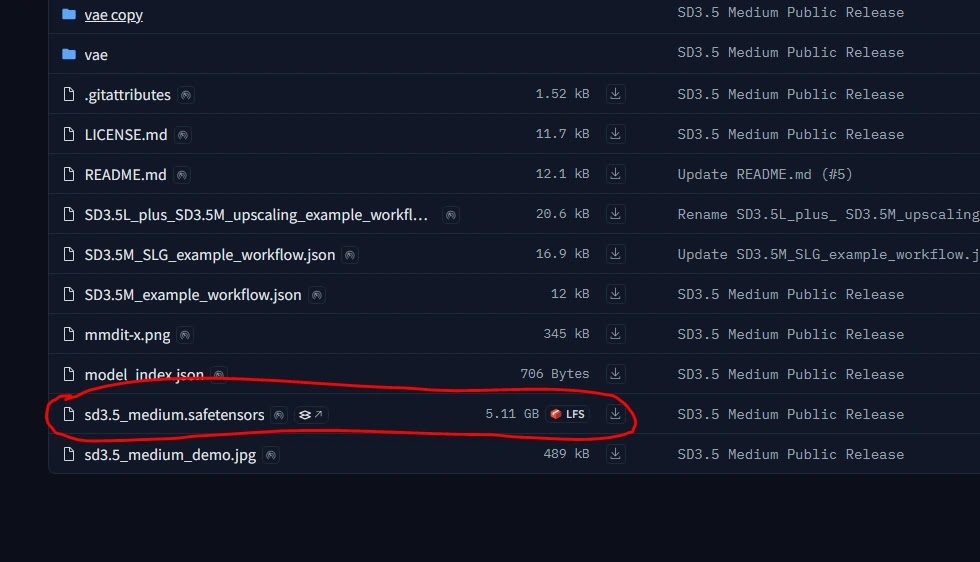
(c) 从StabilityAI的Hugging face下载Stable Diffusion 3.5 Medium的模型权重。
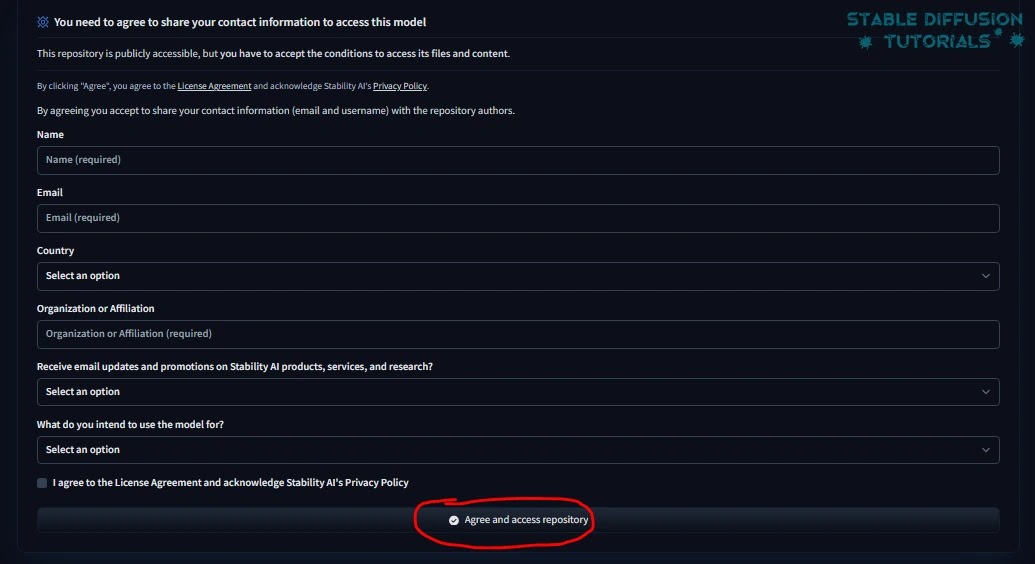
2. 首次下载时,你需要接受他们的许可和协议才能访问他们的存储库。
3. 下载后将它们保存在”ComfyUI/models/checkpoint”文件夹中。
5. 现在,从StabilityAI的Hugging Face下载clip模型(clip_g.safetensors, clip_l.safetensors, 和 t5xxl_fp16.safetensors)并保存在”ComfyUI/models/clip”文件夹中。
由于Stable Diffusion 3.5使用相同的clip模型,如果你是Stable Diffusion 3用户则不需要下载。只需检查所需目录中是否有相应的clip模型即可。
4. 重启ComfyUI使其生效。
类型B: Stable Diffusion 3.5 GGUF量化版本
量化版本在不影响大量图像像素的情况下产生相当好的质量。这对于配备M1/M2芯片的Mac机器来说非常棒。
它消耗较低的GPU并且渲染时间更短。特别是GGUF Loader在GPU上工作以提高VRAM的整体性能。使用T5文本编码器来降低VRAM功耗。
1. 通过在Manager中点击”Update All”来更新ComfyUI。
2. 移动到”ComfyUI/custom_nodes”文件夹。导航到文件夹路径位置并输入”cmd”打开命令提示符。
GGUF Flux用户如果已经安装了这个存储库则不需要重新安装。只需更新即可。移动到”ComfyUI/custom_nodes/ComfyUI-GGUF”文件夹并在命令提示符中输入”git pull”。下载步骤5中提到的SD 3.5量化模型权重并保存到相应文件夹。
3. 然后通过复制并粘贴以下内容到命令提示符来安装和克隆存储库:
git clone https://github.com/city96/ComfyUI-GGUF.git4. 对于便携式用户,移动到”ComfyUI_windows_portable”文件夹。导航到文件夹路径位置并输入”cmd”打开命令提示符。
使用此命令安装依赖项:
git clone https://github.com/city96/ComfyUI-GGUF ComfyUI/custom\_nodes/ComfyUI-GGUF .\\python\_embeded\\python.exe -s -m pip install -r .\\ComfyUI\\custom\_nodes\\ComfyUI-GGUF\\requirements.txt5. 相应存储库中列出了多个模型。下载以下任一预量化模型:
(a) Stable Diffusion 3.5 Large GGUF
(b) Stable Diffusion 3.5 Large Turbo GGUF
(c) Stable Diffusion 3.5 Medium GGUF
将它们保存到”ComfyUI/models/unet”目录。这里,所有的clip模型都已经由CLIP loader处理。所以,不需要下载这个。
但是,如果你想要的话,你可以根据你的GGUF(t5_v1.1-xxl GGUF)模型从Hugging Face下载并保存到”ComfyUI/models/clip”文件夹。
6. 然后重启并刷新ComfyUI使其生效。
工作流程
1. 你可以从StabilityAI的Hugging face下载所有相应的工作流程。
2. 将任何工作流程拖放到ComfyUI。
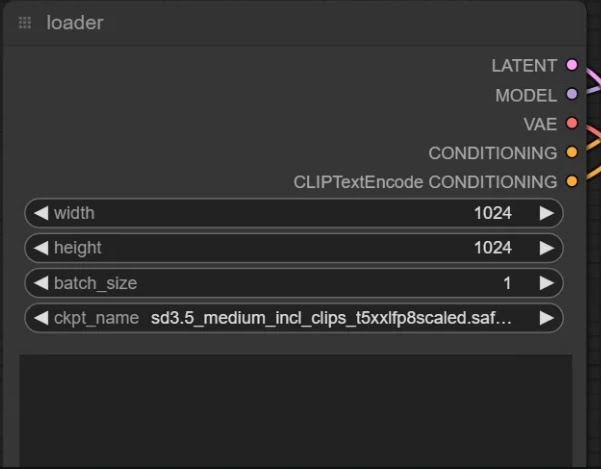
3. 从loader节点加载相关的模型checkpoint。
4. 从KSampler节点设置相关配置。
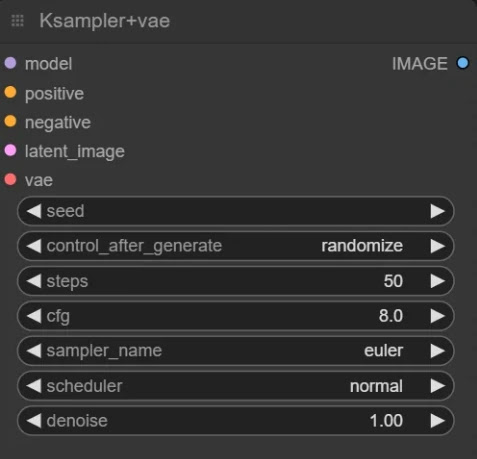
StabilityAI推荐的设置:
| 模型 | CFG | Steps | Sampler |
|---|---|---|---|
| Stable Diffusion 3.5 Large | 4.5 | 28-40 | Euler, SGM Uniform |
| Stable Diffusion 3.5 Large Turbo | 1 | 4 | Euler, SGM Uniform |
我们已经使用推荐设置测试了官方Stable Diffusion 3.5 Large。

这是结果。说实话,这个结果不是精心挑选的。这是我们的第一次生成。还不错。但是裙子有点不真实。
| 参数 | 值 |
|---|---|
| 提示词 | portrait , high quality creative photoshoot of a model , black dress, bluish hair, red lipstick, wearing funky sunglasses, Vogue style, fashion photoshoot, professional makeup, uhd |
| CFG | 4.5 |
| 分辨率 | 1024 x 1024 |
| Steps | 28 |
| 硬件 | NVIDIA RTX 4090 |
| 生成时间 | 22秒 |
你可以从我们的图像提示生成器获取更多提示词想法,该生成器专门设计用于使用Stable Diffusion模型生成图像。
该模型已经使用NLP(自然语言处理)进行了训练,使用基于clip的模型。因此,你可以使用任何LLM,如Tipo LLM扩展等或基于GPT4的LLM,这将改进并生成类似自然人的提示。
让我们尝试另一个。比如一个带有不同配置的恐怖电影场景。

| 参数 | 值 |
|---|---|
| 提示词 | a woman, stands on the roof of a rundown trailer, character with a haunting presence due to her posture, standing in a long dress, gaze locked forward, under ominous weather, realistic, uhd |
| CFG | 4.5 |
| 分辨率 | 1024 x 1024 |
| Steps | 40 |
在这里,结果看起来相当令人满意。提示词遵循度工作得很好。我们的经验是,详细的提示会产生相当不错的结果。
现在,让我们尝试带有人类手指的图像,看看它的表现如何。


更多文章