Qwen3-Omni 全面解析:端到端多模态·实时语音视频·119语言(含技术细节与实操)
这篇文章带你快速上手并深入理解 Qwen3-Omni —— 原生端到端的多语言全模态基础模型。它能同时处理文本、图像、音频、视频,并以文本或自然语音进行实时流式响应。
如果你时间不多,建议先看“快速上手(实操向)”一节直接跑通;想深入原理,可以从“技术报告”一节开始,逐步了解架构与延迟优化的设计取舍。
概述
简介
Qwen3-Omni 是一个原生的端到端多语言全模态基础模型。它能处理文本、图像、音频和视频,并以文本和自然语音两种方式提供实时流式响应。这里先看一下它的几个核心特点:
-
跨模态表现强:文本优先预训练 + 混合多模态训练,原生支持多模态;在不牺牲文本/图像的前提下,把音频和音视频做到了高水准。在 36 个音/音视频基准里,拿下 22 项总体 SOTA、32 项开源 SOTA;ASR、音频理解、语音对话等能力可对标 Gemini 2.5 Pro。
-
多语言覆盖:支持 119 种文本语言、19 种语音输入语言、10 种语音输出语言。
- 语音输入:英语、中文、韩语、日语、德语、俄语、意大利语、法语、西班牙语、葡萄牙语、马来语、荷兰语、印度尼西亚语、土耳其语、越南语、粤语、阿拉伯语、乌尔都语。
- 语音输出:英语、中文、法语、德语、俄语、意大利语、西班牙语、葡萄牙语、日语、韩语。
-
架构设计:采用 Thinker–Talker 的 MoE 方案,配合 AuT 预训练获得强表征,多码本把延迟进一步压低。
-
实时交互:支持实时音视频流式对话,轮流自然,文本或语音都能即时回复。
-
可控性:通过系统提示就能定制行为,容易调出你想要的风格和策略。
-
详细的音频字幕生成器:Qwen3-Omni-30B-A3B-Captioner 现已开源:一个通用的、高度详细的、低幻觉的音频字幕模型,填补了开源社区的一个关键空白。
技术细节(基于 arXiv:2509.17765)
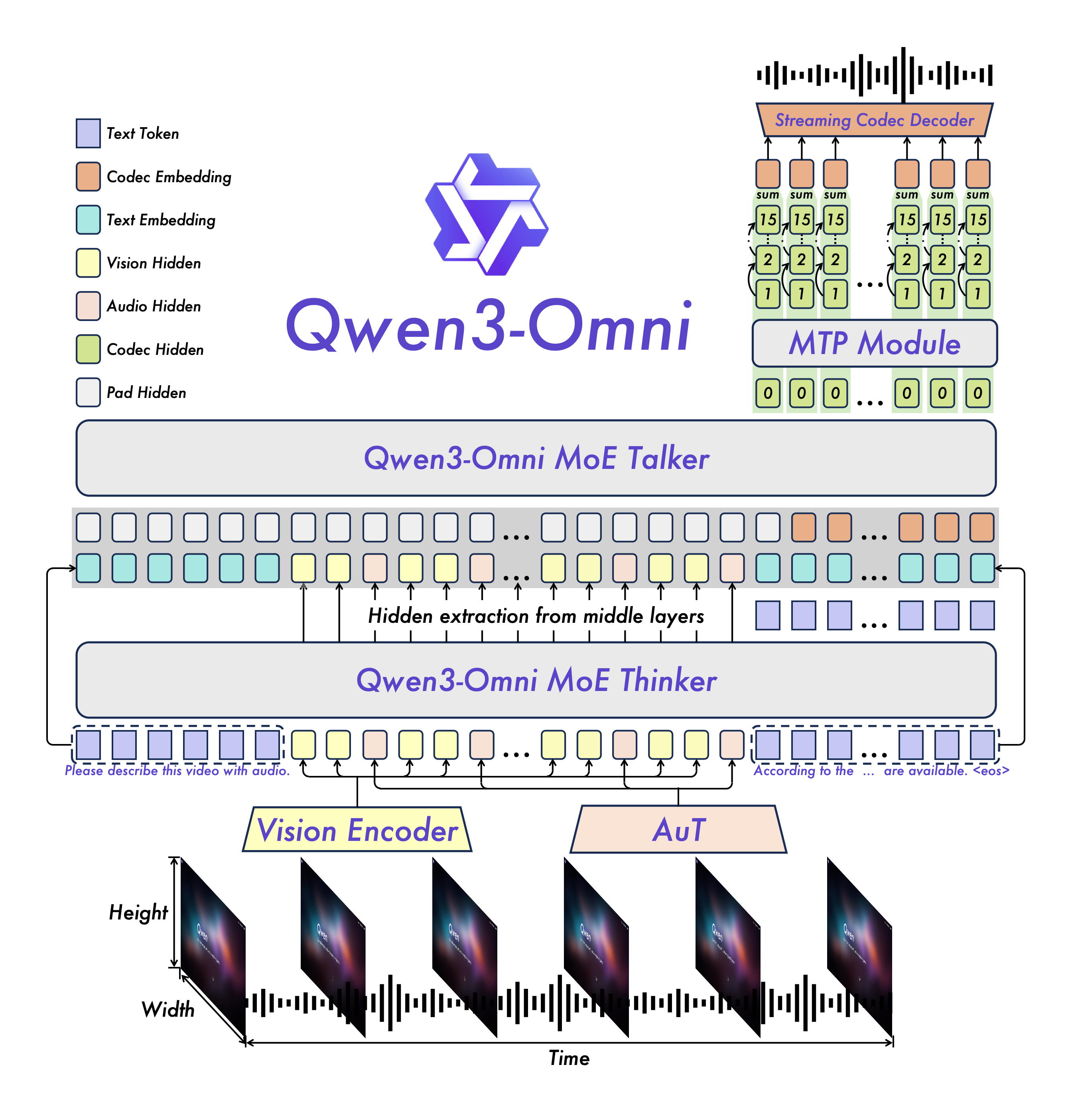
架构设计:Thinker–Talker 怎么配合
- 一个端到端的多模态骨架:同一套模型里完成文本、图像、音频、视频的“看懂 + 说出来”,不搞多段管线那套。
- Thinker(思考):主打跨模态理解与推理,遇到复杂任务可以切到“思考模式”,简单问题就走“非思考模式”。
- Talker(说话):主打实时输出文本/语音,和 Thinker 松耦合,目的是把交互延迟压下来、控制力更强。
- MoE + 多码本:兼顾表示力和吞吐,难活不掉链子,量大时也能跑得动。
语音合成与延迟怎么做
- 多码本离散语音:Talker 自回归预测语音 codec(多码本),表征力强,细节不丢。
- 把块式扩散换成轻量因果卷积:推理更省,第一帧 codec 就能开始流式合成。
- 冷启动端到端首包延迟大约 234 ms:对实时对话来说够用;持续对话时感知延迟还会更低。
- 多轮会话注意一致性:像
use_audio_in_video这类开关要全程一致,否则容易出现缓存/对齐问题。
多语言与多模态覆盖
- 文本交互:支持 119 种语言。
- 语音理解:支持 19 种语言(含中英日韩德俄、粤语、阿拉伯语等)。
- 语音合成:支持 10 种语言(中英法德俄意西葡日韩)。
- 音频/音视频做强的同时,文本/图像不掉线,和同规模单模态模型一个水平。
评测怎么测、结果如何
- 覆盖了 36 个音频/音视频基准,开源 SOTA 32 项、总体 SOTA 22 项。
- 在 ASR、音频理解、语音对话等任务上,可对标 Gemini 2.5 Pro;多项公开基准超过 Seed-ASR、GPT-4o-Transcribe 等闭源基线。
- 关键策略是“文本优先预训练 + 混合多模态训练”,把多模态融合得比较稳,不牺牲基础能力。
型号怎么选、开源情况
- Instruct:Thinker + Talker,全能型,音/视频/文本都能进,音频/文本都能出。
- Thinking:只有 Thinker,主打链式推理,入参同上,输出是文本。
- Captioner:从 Instruct 微调的音频精细字幕模型,细节足、幻觉低,适合标注和理解任务。
- 许可:三款都是 Apache 2.0,研发和商用都友好。
部署怎么配更稳(性能/稳定性)
- 后端:优先 vLLM(低延迟/高吞吐);Transformers 适合做研究与定制,MoE 下注意速度和显存。
- FlashAttention 2:在 Transformers 环境建议开启(需要硬件支持,且用 fp16/bf16 加载)。
- 工具链:安装好
ffmpeg;用qwen-omni-utils处理 Base64/URL/交错多模态,预处理更省心。 - 实时场景:关注音视频 I/O 和编码参数,结合“因果卷积 + 多码本”的路径,保证流式稳定。
参考与资源
- arXiv:Qwen3-Omni Technical Report(arXiv:2509.17765)
- PDF 技术报告: https://github.com/QwenLM/Qwen3-Omni/blob/main/assets/Qwen3_Omni.pdf
- 代码与示例: https://github.com/QwenLM/Qwen3-Omni
- 在线体验:Hugging Face / ModelScope Demo,实时语音/视频交互可在 Qwen Chat 体验。
模型架构
快速上手(实操向)
模型与下载
下面是当前公开的 Qwen3-Omni 模型描述,请根据您的需求选择:
| 模型名称 | 描述 |
|---|---|
| Qwen3-Omni-30B-A3B-Instruct | 包含 Thinker 与 Talker,支持音频/视频/文本输入,输出为音频与文本,适合通用人机交互。 |
| Qwen3-Omni-30B-A3B-Thinking | 仅包含 Thinker,具备链式推理能力,支持音频/视频/文本输入,输出为文本。 |
| Qwen3-Omni-30B-A3B-Captioner | 从 Instruct 下游微调的通用音频精细字幕模型,详细、低幻觉,用于任意音频的描述与标注。 |
在 Transformers 或 vLLM 加载时会自动下载权重;若运行环境不便在线下载,可手动拉取到本地目录:
# 通过 ModelScope(中国大陆推荐)
pip install -U modelscope
modelscope download --model Qwen/Qwen3-Omni-30B-A3B-Instruct --local_dir ./Qwen3-Omni-30B-A3B-Instruct
modelscope download --model Qwen/Qwen3-Omni-30B-A3B-Thinking --local_dir ./Qwen3-Omni-30B-A3B-Thinking
modelscope download --model Qwen/Qwen3-Omni-30B-A3B-Captioner --local_dir ./Qwen3-Omni-30B-A3B-Captioner
# 通过 Hugging Face CLI
pip install -U "huggingface_hub[cli]"
huggingface-cli download Qwen/Qwen3-Omni-30B-A3B-Instruct --local-dir ./Qwen3-Omni-30B-A3B-Instruct
huggingface-cli download Qwen/Qwen3-Omni-30B-A3B-Thinking --local-dir ./Qwen3-Omni-30B-A3B-Thinking
huggingface-cli download Qwen/Qwen3-Omni-30B-A3B-Captioner --local-dir ./Qwen3-Omni-30B-A3B-CaptionerTransformers 安装与用法
建议在全新虚拟环境或使用官方 Docker,避免依赖冲突。
# 如已安装 transformers,请先卸载或新建环境
# pip uninstall transformers
pip install git+https://github.com/huggingface/transformers
pip install accelerate
# 多模态便捷处理工具(支持 base64/URL/交错音频/图像/视频)
pip install qwen-omni-utils -U
# 可选:开启 FlashAttention 2(Transformers 环境可显著降显存;vLLM 已内置)
pip install -U flash-attn --no-build-isolation硬件需支持 FlashAttention 2(模型需以 fp16/bf16 加载)。详细兼容性请参考官方文档。
示例代码(多模态输入 + 文本/语音输出):
小提示:第一次运行建议从 Instruct 模型入手,先验证文本输出;语音合成可在确认显存与依赖就绪后再开启。
# 说明:演示如何用 transformers + qwen-omni-utils 调用 Qwen3-Omni-Instruct
import soundfile as sf
from transformers import Qwen3OmniMoeForConditionalGeneration, Qwen3OmniMoeProcessor
from qwen_omni_utils import process_mm_info
MODEL_PATH = "Qwen/Qwen3-Omni-30B-A3B-Instruct"
# MODEL_PATH = "Qwen/Qwen3-Omni-30B-A3B-Thinking" # 若只需文本输出与推理
# 加载模型(建议开启 FlashAttention 2 以节省显存)
model = Qwen3OmniMoeForConditionalGeneration.from_pretrained(
MODEL_PATH,
dtype="auto",
device_map="auto",
attn_implementation="flash_attention_2",
)
processor = Qwen3OmniMoeProcessor.from_pretrained(MODEL_PATH)
# 构造多模态对话
conversation = [
{
"role": "user",
"content": [
{"type": "image", "image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-Omni/demo/cars.jpg"},
{"type": "audio", "audio": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-Omni/demo/cough.wav"},
{"type": "text", "text": "你看见与听见了什么?请用一句话回答。"}
],
},
]
USE_AUDIO_IN_VIDEO = True # 注意:多轮对话需保持该开关一致
# 预处理
text = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)
audios, images, videos = process_mm_info(conversation, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = processor(
text=text,
audio=audios,
images=images,
videos=videos,
return_tensors="pt",
padding=True,
use_audio_in_video=USE_AUDIO_IN_VIDEO,
)
inputs = inputs.to(model.device).to(model.dtype)
# 生成文本与语音
text_ids, audio = model.generate(
**inputs,
speaker="Ethan", # 选择发声人
thinker_return_dict_in_generate=True,
use_audio_in_video=USE_AUDIO_IN_VIDEO,
)
# 解码文本
text = processor.batch_decode(
text_ids.sequences[:, inputs["input_ids"].shape[1] :],
skip_special_tokens=True,
clean_up_tokenization_spaces=False,
)
print(text)
# 保存音频
if audio is not None:
sf.write(
"output.wav",
audio.reshape(-1).detach().cpu().numpy(),
samplerate=24000,
)vLLM 使用要点
在 vLLM 中,可将由 processor.apply_chat_template 得到的 prompt 与多模态数据一起传入后端:
text = processor.apply_chat_template(messages, add_generation_prompt=True, tokenize=False)
inputs = {
"prompt": text,
"multi_modal_data": {},
"mm_processor_kwargs": {
"use_audio_in_video": True, # 与多轮对话中的设置保持一致
},
}注意:多轮会话中 use_audio_in_video 必须保持一致,否则可能出现缓存错位或结果异常。
本地 Web UI Demo
安装依赖:
pip install gradio==5.44.1 gradio_client==1.12.1 soundfile==0.13.1启动示例:
# Instruct(vLLM 后端)
python web_demo.py -c Qwen/Qwen3-Omni-30B-A3B-Instruct
# Instruct(Transformers 后端,含语音合成)
python web_demo.py -c Qwen/Qwen3-Omni-30B-A3B-Instruct --use-transformers --generate-audio
# Instruct(Transformers + FlashAttention 2)
python web_demo.py -c Qwen/Qwen3-Omni-30B-A3B-Instruct --use-transformers --generate-audio --flash-attn2# Thinking(vLLM 后端)
python web_demo.py -c Qwen/Qwen3-Omni-30B-A3B-Thinking
# Thinking(Transformers 后端)
python web_demo.py -c Qwen/Qwen3-Omni-30B-A3B-Thinking --use-transformers
# Thinking(Transformers + FlashAttention 2)
python web_demo.py -c Qwen/Qwen3-Omni-30B-A3B-Thinking --use-transformers --flash-attn2# Captioner(vLLM 后端)
python web_demo_captioner.py -c Qwen/Qwen3-Omni-30B-A3B-Captioner
# Captioner(Transformers 后端)
python web_demo_captioner.py -c Qwen/Qwen3-Omni-30B-A3B-Captioner --use-transformers更多文章