重磅!OpenAI 发布全能推理模型 o3 与高效型 o4-mini
关键要点
OpenAI 于 2025 年 4 月 16 日发布了 o3 和 o4-mini 模型,可能是目前最先进的推理模型,支持视觉推理和工具使用。
研究表明,o3 在编码、数学、科学和视觉任务中表现优异,o4-mini 则更适合快速、低成本的推理任务。
证据显示,这两个模型在安全性和性能上都有显著改进,包括减少重大错误和增强的安全拒绝提示。
模型功能与特性
OpenAI 的 o3 和 o4-mini 模型旨在处理复杂问题,配备了如网络搜索、Python 分析和图像生成的工具。o3 特别擅长编码、数学、科学和视觉任务,而 o4-mini 则优化用于高容量任务,提供快速且经济的解决方案。这两个模型都能参考过去的对话,提供更个性化的交互体验。
例如,o3 在处理复杂查询时表现出色,而 o4-mini 因其效率而适合需要快速响应的场景。这些能力通过工具的使用得到了增强,例如通过网络搜索获取实时信息或通过 Python 分析进行数据处理。
性能改进
与之前的 o1 模型相比,o3 减少了 20% 的重大错误,尤其在编程、商业和创意构思方面表现出色。o4-mini 在非 STEM 任务和数据科学上超过了 o3-mini,并因其效率而具有更高的使用限制。这些改进使得模型在需要高准确度和效率的应用中更具吸引力。
此外,两个模型在指令遵循和对话自然性上也有显著提升,能够更好地理解用户意图并提供更自然的交互体验。例如,它们可以参考之前的对话内容,为用户提供更个性化的响应。
基准测试结果
为了评估这些新模型的性能,OpenAI 提供了多个基准测试的详细比较,涵盖数学、科学、编码和视觉推理等领域。以下是关键基准测试的结果:
| 模型 | AIME 2024 | AIME 2025 | Codeforces ELO | GPQA Diamond | MMMU | MathVista | CharXiv-Reasoning | SWE-Bench | Deep Research |
|---|---|---|---|---|---|---|---|---|---|
o1 | 74.3 | 79.2 | 1891 | 78.0 | 77.6 | 71.8 | 55.1 | 48.9 | 8.12 |
o3-mini | 87.3 | 86.5 | 2073 | 77.0 | - | - | - | 49.3 | 13.40 |
o3 (no tools) | 91.6 | 88.9 | 2706 | 83.3 | 82.9 | 86.8 | 78.6 | 69.1 | 20.32/24.90* |
o4-mini (no tools) | 93.4 | 92.7 | 2719 | 81.4 | 81.6 | 84.3 | 72.0 | 68.1 | 14.28/17.70* |
这些基准测试包括:
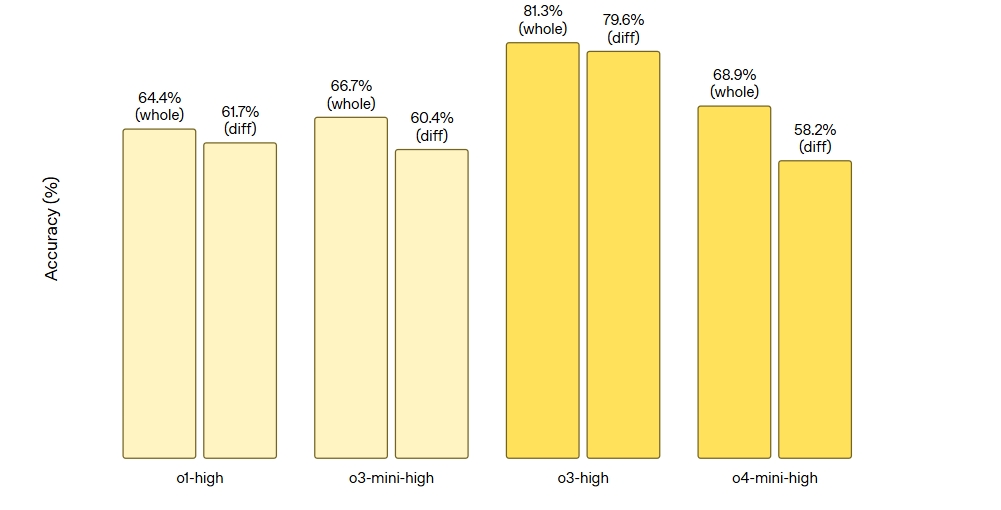
AIME:美国邀请数学考试,测试高级数学能力,o4-mini在 2024 和 2025 年分别达到 93.4% 和 92.7% 的准确率。GPQA:通用问题回答,专注于钻石级博士科学问题,o3无工具得分 83.3%,o4-mini无工具得分 81.4%。MMMU:大学级视觉问题解决,o3和o4-mini分别得分 82.9% 和 81.6%。MathVista:视觉数学推理,o3得分 86.8%,o4-mini得分 84.3%。CharXiv-Reasoning:科学图形推理,o3得分 78.6%,o4-mini得分 72.0%。SWE-Bench:验证的软件工程任务,o3得分 69.1%,o4-mini得分 68.1%。Deep Research:跨学科专家级问题,工具使用下o3得分 24.9%,o4-mini得分 17.7%,而4o+ 浏览得分 51.5%,o3+Python+ 浏览得分 49.7%。
这些结果显示,o3 和 o4-mini 在多个领域表现优异,尤其是在工具使用的情况下。
成本与性能
o3 相较于 o1 提供了性能提升,而 o4-mini 相较于 o3-mini 更智能且成本更低,特别是在 AIME 和 GPQA 评估中。这使得它们在现实世界应用中更具吸引力,平衡了性能和成本。
安全措施
安全是 OpenAI 的首要任务。新模型包括针对生物风险、恶意软件和越狱的新拒绝提示,以防止生成有害或危险内容。推理 LLM 监控在人类红队测试中成功标记了约 99% 的危险对话。根据 OpenAI 的准备框架(更新我们的准备框架),这些模型在生物和化学风险、网络安全和 AI 自我改进类别中均低于”高”阈值。详细的安全结果可在系统卡中找到(o3 和 o4-mini 系统卡)。
生物风险指防止模型生成与生物威胁相关的有害内容,恶意软件指防止生成恶意代码,越狱指防止模型被操纵执行非预期任务。这些措施通过重建安全训练数据和系统级缓解措施来实现,确保模型在最严格的安全测试中表现良好。
新功能
除了新模型,OpenAI 还推出了 Codex CLI,这是一个轻量级的终端编码代理,最大化利用 o3 和 o4-mini 的推理能力,并计划支持即将推出的 GPT-4.1。Codex CLI 支持通过截图或低保真草图进行多模态推理,并访问本地代码,是开发者的多功能工具。它完全开源,可在 GitHub 上找到(Codex CLI GitHub)。
此外,OpenAI 启动了一项 100 万美元的倡议,支持使用 Codex CLI 和 OpenAI 模型的项目。补助金以 25,000 美元的 API 信用增量形式提供,感兴趣的各方可通过表单提交提案(Codex 开源基金)。
访问与可用性
o3 和 o4-mini 现已对 ChatGPT Plus、Pro 和 Team 用户开放,取代了 o1、o3-mini 和 o3-mini-high 模型。企业用户将在一周内获得访问,免费用户可通过作曲器中的”思考”功能体验 o4-mini。对于开发者,API 访问通过聊天完成和响应 API 提供,文档可在 OpenAI API 文档中找到。
更多文章