Microsoft TRELLIS 教程 - 开源文生3D、图生3D模型部署指南
4 min read
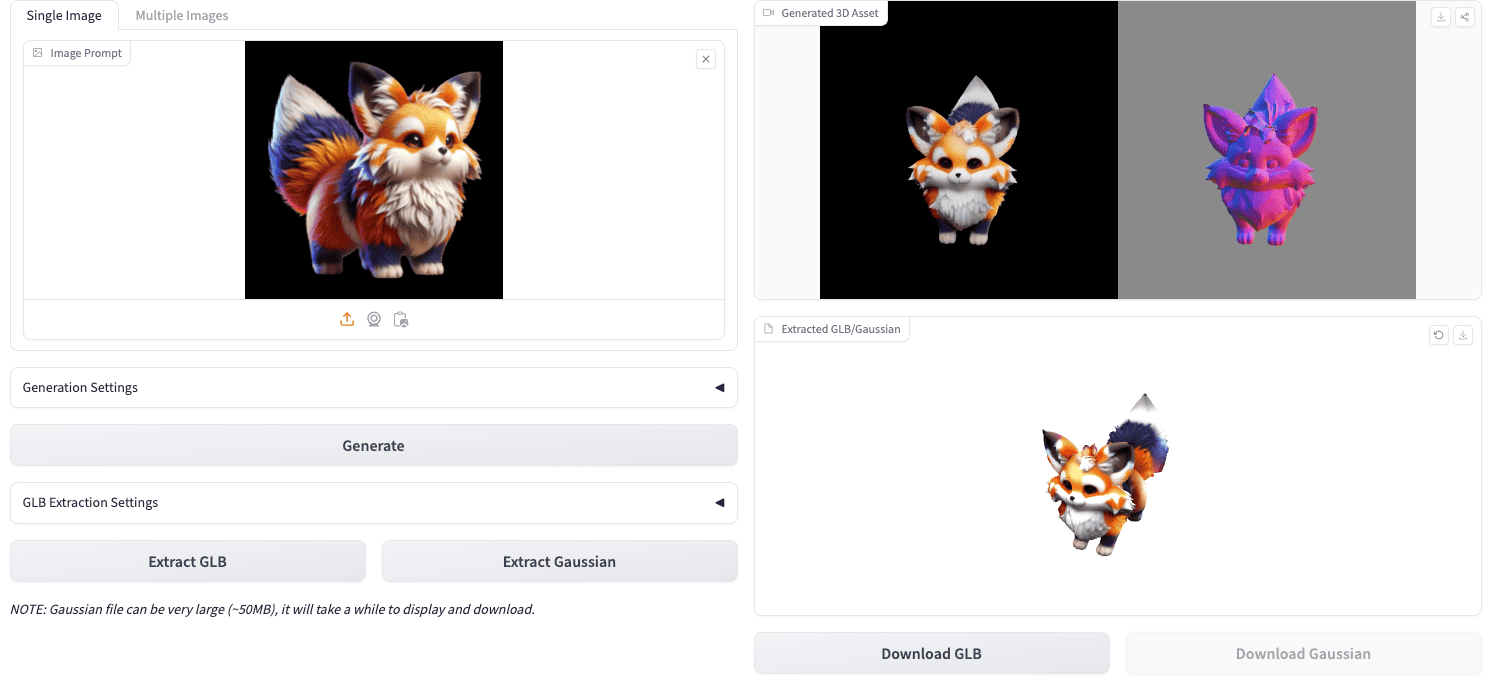
TRELLIS 简介
TRELLIS 是微软开源的一个大规模3D资产生成模型,支持从文本或图像生成高质量的3D内容。它采用结构化3D潜空间方法,能够实现可扩展且多功能的3D生成。
主要特点:
- 支持图生3D和文生3D两种生成模式
- 采用结构化3D潜空间方法,生成质量更高
- 提供多种3D表示格式(高斯点云、辐射场、网格等)
- 开源且易于部署使用
- 支持导出GLB/PLY等标准3D文件格式
在线示例
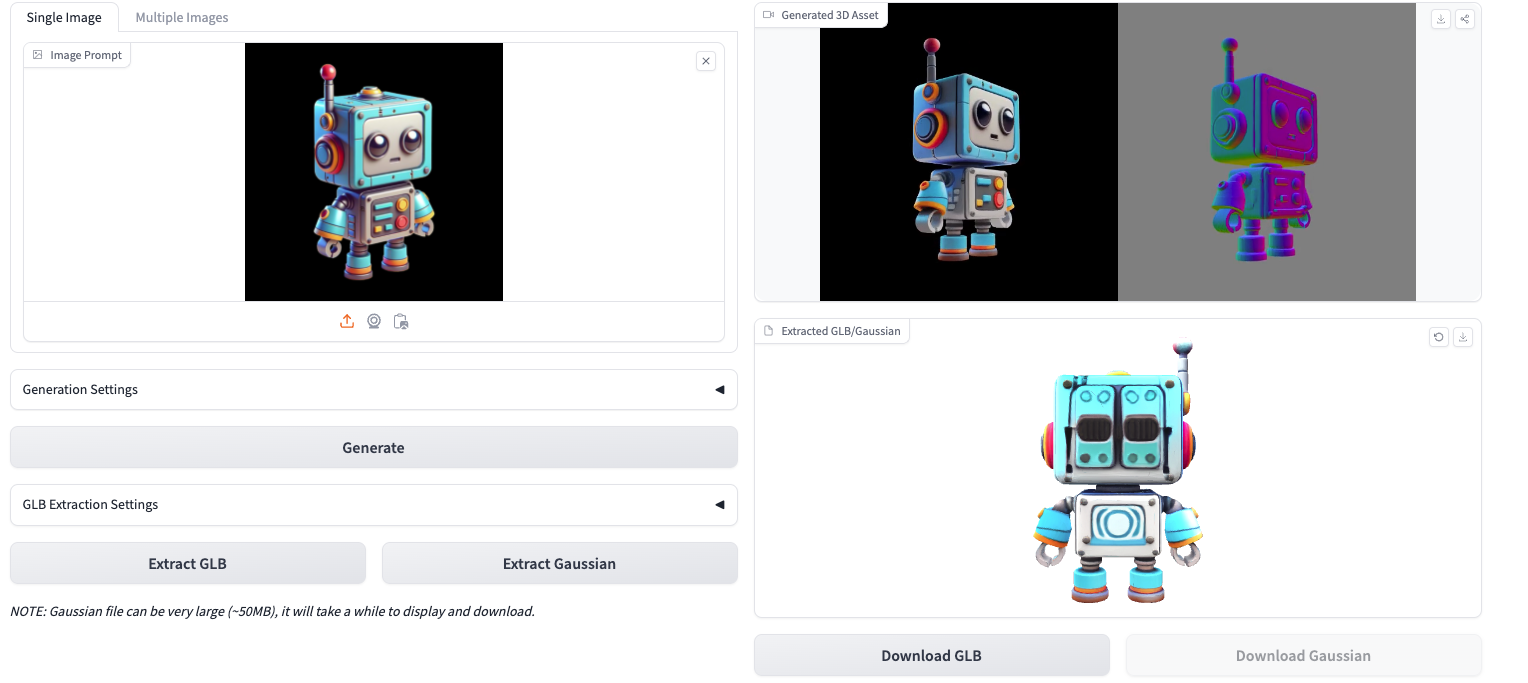
快速开始
环境要求
- CUDA 兼容的 NVIDIA GPU (推荐 RTX 30/40 系列)
- CUDA Toolkit 11.8 或 12.2
- Python 3.8+
- conda 环境管理工具
安装步骤
- 克隆项目代码:
git clone https://github.com/microsoft/TRELLIS.git
cd TRELLIS- 创建并激活conda环境:
# 使用CUDA 11.8
. ./setup.sh --new-env --basic --xformers --flash-attn --diffoctreerast --spconv --mipgaussian --kaolin --nvdiffrast
# 如果使用CUDA 12.2,需要手动安装依赖
conda create -n trellis python=3.10
conda activate trellis
pip install -r requirements.txt- 下载预训练模型:
目前可用的预训练模型包括:
- TRELLIS-image-large: 大型图生3D模型 (1.2B参数)
- TRELLIS-text-base: 基础文生3D模型 (342M参数)
- TRELLIS-text-large: 大型文生3D模型 (1.1B参数)
- TRELLIS-text-xlarge: 超大型文生3D模型 (2.0B参数)
你可以从Hugging Face下载这些模型。
使用教程
图生3D示例
import os
# 设置后端
os.environ['SPCONV_ALGO'] = 'native' # 可选 'native' 或 'auto'
import imageio
from PIL import Image
from trellis.pipelines import TrellisImageTo3DPipeline
from trellis.utils import render_utils, postprocessing_utils
# 加载模型
pipeline = TrellisImageTo3DPipeline.from_pretrained("JeffreyXiang/TRELLIS-image-large")
pipeline.cuda()
# 加载输入图片
image = Image.open("input.png")
# 运行生成
outputs = pipeline.run(
image,
seed=1,
# 可选参数
# sparse_structure_sampler_params={
# "steps": 12,
# "cfg_strength": 7.5,
# },
# slat_sampler_params={
# "steps": 12,
# "cfg_strength": 3,
# },
)
# 渲染预览视频
video = render_utils.render_video(outputs['gaussian'][0])['color']
imageio.mimsave("preview_gs.mp4", video, fps=30)
# 导出3D文件
glb = postprocessing_utils.to_glb(
outputs['gaussian'][0],
outputs['mesh'][0],
simplify=0.95, # 网格简化比例
texture_size=1024, # 纹理大小
)
glb.export("output.glb")
# 保存点云数据
outputs['gaussian'][0].save_ply("output.ply")Web演示界面
TRELLIS提供了一个基于Gradio的Web演示界面。运行以下命令启动:
# 安装额外依赖
. ./setup.sh --demo
# 启动服务
python app.py启动后可以通过浏览器访问Web界面。
最佳实践
- 输入图片建议:
- 使用清晰、对比度适中的图片
- 物体轮廓要清晰可见
- 避免复杂背景和遮挡
- 生成参数调优:
- 适当增加采样步数可以提高质量
- 调整cfg_strength参数控制生成的保真度
- 建议多尝试不同的随机种子
- 性能优化:
- 使用native后端可以加快首次运行速度
- 适当降低纹理分辨率可以减少显存占用
- 导出时根据需要调整网格简化比例
常见问题
- 显存不足:
- 降低batch size
- 使用较小的模型版本
- 减少采样步数
- 生成质量问题:
- 检查输入图片质量
- 适当增加采样步数
- 调整cfg_strength参数
- 导出文件过大:
- 增加网格简化比例
- 降低纹理分辨率
- 选择合适的文件格式
参考资源
更多文章

Qwen3-Next 系列全解析:80B-A3B 的混合架构,Instruct 与 Thinking 双线能力进化

DeepSeek V3.1:混合推理、强劲编程与 Agent 能力,支持Claude Code,性价比再升级

Qwen-Image-Edit 图像编辑介绍与 ComfyUI 使用指南

沉浸式翻译插件重大安全漏洞:网页快照功能导致用户敏感信息大规模泄露

GLM-4.5技术报告与应用体验:国产智能体大模型新标杆

Win11Debloat 深度指南:一键精简 Windows 11,告别臃肿,提升系统性能

阿里Qwen-MT翻译模型重磅升级:92种语言、秒级响应,挑战GPT-4翻译霸主地位

Kimi K2如何凭借三大创新炼成万亿开源模型?
Docker运行macOS教程:Linux系统完整配置与部署指南