微软 OmniParser V2.0 重磅发布:AI 视觉解析迎来重大升级,自动化与可访问性迈向新高度
微软近日正式发布 OmniParser V2.0,这款强大的工具能够将图形用户界面 (GUI) 的屏幕截图转化为结构化数据。作为人工智能 (AI) 领域的一项重大突破,OmniParser V2.0 通过增强大型语言模型 (LLM) 与屏幕上视觉元素的交互能力,为自动化和可访问性开辟了新的可能性。
OmniParser V2.0 旨在提高 AI 在理解和操作用户界面方面的效率。通过将屏幕截图转化为结构化数据,该工具让 AI 模型能够识别、理解并与界面上的元素进行交互,从而实现更智能、更高效的应用自动化和用户辅助功能。
主要特性与改进:
-
速度大幅提升: OmniParser V2.0 的延迟相比上一代产品降低了 60%,在高配置 GPU(如 A100 和 4090 型号)上的平均处理时间分别仅为 0.6 秒和 0.8 秒,极大地提升了处理效率。
-
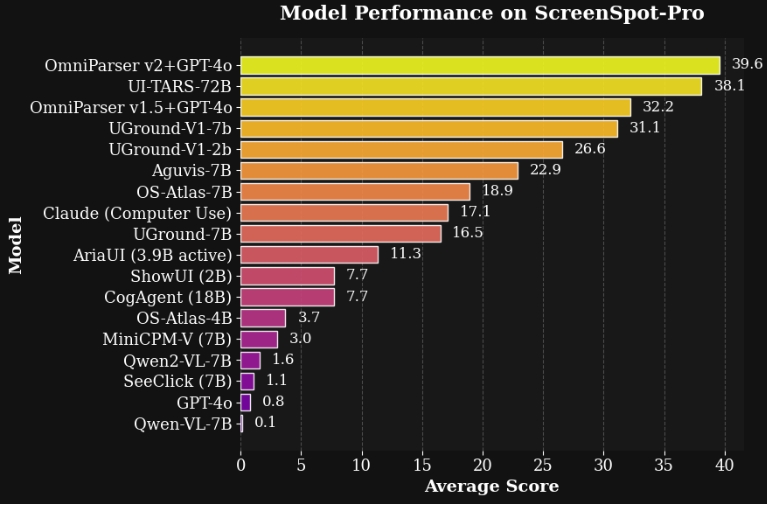
精度显著提高: 在 ScreenSpot Pro 基准测试中,OmniParser V2.0 在检测交互元素方面的平均准确率达到了 39.6%,相较以往版本有了质的飞跃。
-
强大的输入与输出能力:
- 输入: 支持来自 Windows、移动设备和 Web 应用等多个平台的屏幕截图。
- 输出: 生成交互元素的结构化表示,包括可点击区域的位置数据和 UI 组件的功能描述。
-
与 LLM 的无缝集成: 通过统一的 OmniTool 接口,OmniParser V2.0 可与 OpenAI 的 GPT-4o、DeepSeek R1、Qwen 2.5VL 和 Anthropic Sonnet 等多种 AI 模型集成,为开发者创建自动化测试工具、辅助功能解决方案等提供了便利。
技术升级:
OmniParser V2.0 采用了微调的 YOLOv8 模型以及 Florence-2 基础模型,从而增强了其对界面元素的理解能力。训练数据集也得到了扩展,包含了关于图标及其功能的更全面信息,这显著提高了模型检测小型 UI 组件的性能。
快速开始
按照下面安装conda虚拟环境并安装对应依赖即可
- 环境准备
conda create -n "omni" python==3.12
conda activate omni
pip install -r requirements.txt- 下载模型
rm -rf weights/icon_detect weights/icon_caption weights/icon_caption_florence
huggingface-cli download microsoft/OmniParser-v2.0 --local-dir weights
mv weights/icon_caption weights/icon_caption_florence- 运行演示
- 使用 Jupyter Notebook:
打开
demo.ipynb查看示例代码 - 使用 Web 界面:
python gradio_demo.py
广泛的应用场景:
OmniParser V2.0 在以下领域具有广泛的应用前景:
-
UI 自动化: 通过使 AI 代理能够与 GUI 交互,从而实现重复性任务的自动化。
-
辅助功能解决方案: 通过提供可由辅助技术解读的结构化数据,帮助残障用户更便捷地使用各种应用。
-
用户界面分析: 基于从屏幕截图中提取的结构化数据,对用户界面进行分析和改进。
微软表示,OmniParser V2.0 的发布是 AI 视觉解析领域的重要里程碑。凭借其卓越的速度、精度和集成能力,OmniParser V2.0 将成为开发者和企业在 AI 驱动的技术解决方案领域中的重要工具,为用户带来更智能、更便捷的体验。随着技术的不断发展,OmniParser V2.0 有望在未来推动更多创新应用,为各行各业带来深远影响。
相关链接
更多文章