Kimi K2如何凭借三大创新炼成万亿开源模型?

月之暗面(Moonshot AI)近日发布的Kimi K2技术报告,揭示了一款万亿级(Trillion-parameter)开源模型的诞生细节。不同于产品发布会,这份长达32页的技术文档,为我们提供了一个深入理解前沿AI模型背后核心技术的窗口。报告详尽阐述了Kimi K2如何在训练稳定性、数据效率和模型架构上进行创新,最终在多个关键基准上取得了SOTA(State-of-the-art)的性能。
本文将为您深度解读这份报告,剖析支撑Kimi K2强大性能的三大技术支柱。
支柱一:MuonClip优化器——为万亿模型训练打造的“超级稳定器”
训练超大规模语言模型如同驾驶一架性能极强的实验性飞行器,任何微小的扰动都可能导致灾难性的“训练崩溃”(即“损失尖峰”)。Kimi团队在报告中指出,为了追求更高的训练效率(即“token效率”),他们采用了Muon优化器,但发现这种优化器在扩大模型规模时,更容易出现“注意力 logits 爆炸”的问题,从而导致训练不稳定 。
为解决这一世界性难题,团队提出了名为 MuonClip 的创新优化器 。其核心是一项名为 QK-Clip 的新技术,其工作原理可以理解为一个精密的“逐头(per-head)自适应调节器”
- 监控与干预:QK-Clip会实时监控模型中每个注意力头的内部计算值(logits) 。
- 精准调节:一旦发现某个头的数值超过预设的安全阈值
τ,它会立即启动,并只对这个“异常”的头进行缩放,而不影响其他正常工作的头 。 - 自动停用:当训练过程稳定下来,所有头的数值都回归正常范围后,QK-Clip 会自动“休眠”,不再对模型进行干预,实现了最小化干预原则 。
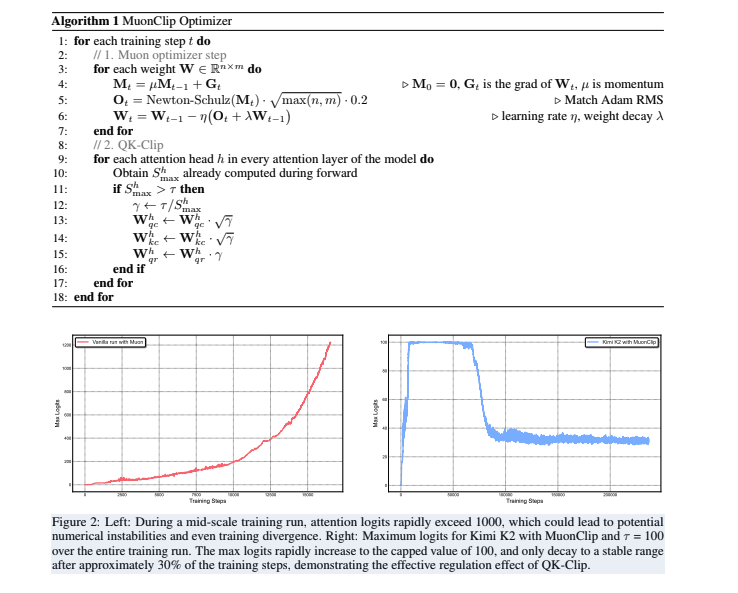
图:左侧为未使用稳定器的训练,注意力Logits迅速飙升;右侧为使用MuonClip的Kimi K2,Logits被有效控制在阈值100以下,并在后期稳定下来。
报告强调,在长达 15.5万亿 训练token的过程中,Kimi K2 没有出现一次损失尖峰 。这一成果证明了MuonClip在保障大规模模型训练稳定性上的卓越效果,为业界探索更大规模的模型提供了宝贵的工程经验。
支柱二:数据再利用的艺术——从“重复灌输”到“知识改写”
在高质量数据日益成为瓶颈的当下,如何从有限的数据中提取更多价值,是所有AI公司的核心议题。简单的多轮次重复(multi-epoch)训练同样的数据,不仅收益递减,还会导致模型过拟合,失去泛化能力 。
Kimi K2团队为此设计了一套精密的 数据改写(Rephrasing) 流程,旨在提升“token效用”,即每个token对模型训练的有效贡献 。
报告中详细介绍了针对两大领域的改写策略:
- 知识数据:通过精心设计的提示词(prompt),引导一个强大的辅助LLM,从不同风格和视角重写原始文本 。为了处理长文档,还采用了“分块自回归生成”技术,确保全局信息不丢失 。
- 数学数据:借鉴了SwallowMath的方法,将高质量的数学文档改写为“学习笔记”风格,以增强模型的推理能力 。
实验数据有力地证明了这一策略的有效性。在SimpleQA准确率测试中,使用改写10次、训练1轮的数据,模型准确率达到 28.94%,显著高于使用原始数据重复训练10轮的 23.76% 。这表明,通过高质量的改写,模型能更深入地吸收知识,而非机械记忆。
支柱三:高稀疏MoE架构——在万亿参数和推理效率间取得平衡
Kimi K2的底层是一个拥有 1.04万亿 总参数的 混合专家(Mixture-of-Experts, MoE) 模型,但在每次前向传播中,仅激活 326亿 参数 。MoE架构允许模型拥有巨大的知识容量,同时通过“稀疏激活”机制保持相对较低的推理成本 。
Kimi团队通过其“稀疏性缩放定律(Sparsity Scaling Law)”研究发现,在激活参数量固定的情况下,增加专家总数(即提高稀疏度)能持续降低模型的验证损失,带来性能提升 。Kimi K2选择了48的稀疏度(384个专家中激活8个),在性能和成本间取得了平衡。
报告中,Kimi K2与DeepSeek-V3的架构对比,清晰地揭示了其独特的设计取舍:
| 架构参数 | DeepSeek-V3 | Kimi K2 | 变化 | 技术考量 |
|---|---|---|---|---|
| 总参数 | 671B | 1.04T | ▲ 54% | 根据缩放定律,增加总参数能提升模型性能上限 。 |
| 专家总数 | 256 | 384 | ▲ 50% | 提高稀疏度,这是提升MoE模型性能的关键 。 |
| 激活参数 | 37B | 32.6B | ▼ 13% | 在保证性能的同时,进一步降低单次推理的计算量 。 |
| 注意力头数 | 128 | 64 | ▼ 50% | 显著降低长文本(long-context)场景下的推理开销和内存占用,这对需要处理复杂上下文的智能体(Agent)任务至关重要 。 |
这种 “增加模型深度(更多专家)” 与 “降低推理宽度(更少注意力头)” 的组合拳,使Kimi K2在理论性能和实际应用效率之间找到了一个甜点,尤其强化了其在未来核心应用场景——长上下文处理和Agentic AI——上的潜力。
结论
Kimi K2的技术报告不仅是一次成果展示,更是一次宝贵的技术路线分享。通过创新的MuonClip优化器解决了超大模型训练的稳定性难题;通过数据改写策略提升了数据利用效率;并通过精心设计的MoE架构在模型性能与推理成本之间取得了精妙平衡。这些技术细节共同构成了Kimi K2强大能力的基石,也为整个开源社区探索AGI(通用人工智能)的未来提供了极具价值的参考。
技术报告下载
更多文章