GLM-4.5技术报告与应用体验:国产智能体大模型新标杆

2025年7月28日,智谱AI发布新一代旗舰模型GLM-4.5,这款专为智能体应用打造的基础模型在Hugging Face和ModelScope平台同步开源,采用MIT协议,商用门槛极低。本文结合GLM-4.5技术报告及用户实际体验,从技术突破、性能表现、实际应用及生态构建等维度进行综合评价,探讨其在国产大模型领域的意义。
技术突破:原生智能体与高效架构
1. 混合专家(MoE)架构
GLM-4.5采用混合专家(MoE)架构,推出两个版本:
GLM-4.5:总参数量3550亿,激活参数320亿。GLM-4.5-Air:总参数量1060亿,激活参数120亿。
MoE架构通过稀疏激活大幅降低计算成本,同时保持高性能。相比竞品如DeepSeek-R1(参数量为GLM-4.5的两倍)和Kimi-K2(参数量为GLM-4.5的三倍),GLM-4.5在SWE-Bench Verified等榜单上展现出更高参数效率,位列性能/参数比帕累托前沿。这种高效架构使其在推理速度和成本控制上具有明显优势,API调用价格低至输入0.8元/百万tokens、输出2元/百万tokens,远低于国际主流模型(如OpenAI、Anthropic)。高速版生成速度可达100 tokens/秒,满足低延迟、高并发场景需求。
2. 原生智能体能力
GLM-4.5首次在单个模型中原生融合推理、编码和智能体能力,定位为“Agent-native Foundation Model”。其设计理念是将通用智能能力(如任务理解、规划分解、工具调用和执行反馈)深度整合,超越传统聊天机器人的功能边界。技术报告指出,模型在15万亿token的通用数据预训练基础上,额外在8万亿token的代码、智能体和推理数据上进行微调,并通过强化学习优化工具调用和多轮任务执行能力。
后训练阶段采用监督微调(SFT)、强化学习(RL)及专家蒸馏技术,显著提升模型在复杂推理、代码生成和工具调用场景的表现。例如,GLM-4.5支持结构化工具调用(如输出<tool_call>数据结构)和链式思维(Chain-of-Thought),使其特别适合开发AI Agent或Copilot应用。
3. 兼容性和开源策略
GLM-4.5的API兼容Claude Code、Cline、Roo Code等主流代码智能体框架,降低开发者迁移成本。模型权重在Hugging Face和ModelScope平台遵循MIT协议开源,商用限制极少,为企业和个人开发者提供了灵活的二次开发空间。这种开放策略不仅推动了生态建设,还吸引了大量开发者参与,助力构建活跃的应用生态。
技术细节模块分析
预训练与数据策略
GLM-4.5的预训练分为两个阶段:
- 通用预训练:使用15万亿token的通用语料库,覆盖广泛的文本数据,确保模型具备通用语言能力。
- 领域增强预训练:在7万亿token的代码和推理语料库上进一步训练,针对编码和复杂推理任务进行优化。
预训练后,模型进入后训练阶段,利用中等规模的特定领域数据集(如指令数据)进行监督微调(SFT),以提升在关键下游任务中的表现。这种分阶段训练策略在保证通用能力的同时,显著增强了模型在智能体和推理场景的专项能力。
强化学习:Slime架构与代理能力优化
GLM-4.5的强化学习(RL)训练基于智谱开源的Slime框架,专为大规模模型设计,解决复杂代理任务中的瓶颈。Slime的创新点包括:
- 灵活的混合训练架构:支持同步共置训练和异步分解训练。异步模式将数据生成与训练解耦,适用于数据生成缓慢的代理任务,确保GPU利用率最大化。
- 面向代理的解耦设计:将部署引擎与训练引擎分离,在不同硬件上独立运行,解决长尾延迟问题,加速长期代理任务的训练。
- 混合精度加速:数据生成采用高效FP8格式,训练循环保留BF16格式,在不牺牲质量的前提下提升生成速度。
后训练阶段通过监督微调和强化学习优化代理能力,融合GLM-4-0414的通用能力和GLM-Z1的推理能力,重点增强代理编码、深度搜索和工具使用。训练过程包括:
- 推理优化:采用基于难度的课程训练,在64K上下文窗口中进行单阶段强化学习,优于渐进式调度。动态采样温度和自适应裁剪技术确保STEM问题上的策略稳定性。
- 代理任务训练:针对信息搜索QA和软件工程任务,基于人在环提取和网页内容混淆生成合成数据,编码任务则由真实SWE任务反馈驱动。
性能表现:基准测试与真实场景
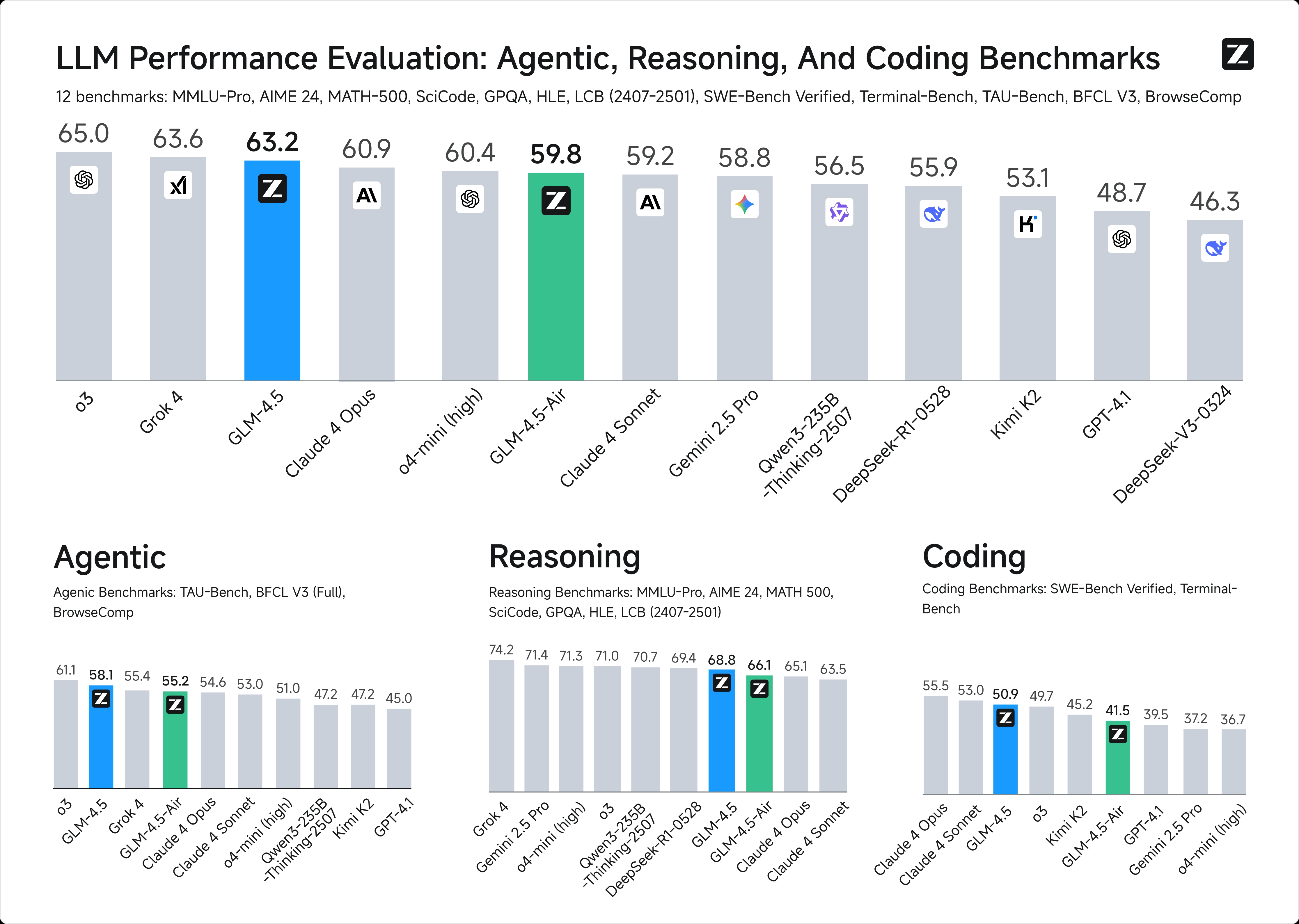
1. 基准测试:全球第三,国产第一
GLM-4.5在12项权威基准测试(包括MMLU Pro、AIME 24、MATH 500、SciCode、GPQA、HLE、LiveCodeBench等)中综合得分位列全球第三、国产第一、开源模型第一。尤其在推理类评测(如MATH、GSM8K、BBH)中,模型展现出强大的多步骤逻辑推理和数学问题解决能力。
在代码能力方面,GLM-4.5在SWE-Bench Verified榜单上表现出色,优于参数量更大的DeepSeek-R1和Kimi-K2。智谱团队还组织了52项涵盖六大开发方向的真实任务评测,与Claude-4-Sonnet、Kimi-K2、Qwen3-Coder等主流模型对比,结果显示GLM-4.5在多轮交互、工具调用可靠性和任务完成度上领先其他开源模型,尽管与Claude-4-Sonnet仍有一定差距。
2. 真实场景表现
用户实测表明,GLM-4.5在实际应用中表现出色,尤其在复杂代码生成、网页开发和创意内容生成场景。例如,用户通过简单提示词(如“做一个Google搜索网站”或“开发一个B站风格的网页端Demo”)即可生成可交互的搜索引擎或支持弹幕的类B站网页。这些案例得益于模型在前端网页设计、后端数据库管理及工具调用接口的原生支持。
在创意写作测试中(如小说创作《气味调配师的最后订单》),GLM-4.5在世界观构建、氛围渲染和情节推动方面表现不俗,与Claude、Gemini等模型相比,整体流畅度和指令遵循能力相当。用户反馈其生成结果“几乎看不出是AI写的”,尤其在视觉设计和交互体验上更符合用户预期。
数学推理测试中,GLM-4.5在标准化学术问题(如大学入学考试数学题)上表现严谨,多数情况下能直接输出正确答案。开启“思考模式”后,模型在复杂推理任务中的准确性进一步提升,展现出强大的逻辑推理能力。
这里我们看官方的示例
- 🧩 赛博朋克卡牌 AI 生成器
- 🌟 Pokémon Pokédex Live
- 📚 中世纪诗歌 Gen
用户体验:高性价比与易用性
1. 成本与效率
GLM-4.5的低成本和高效率是用户体验的核心亮点。API定价远低于国际竞品,高速版生成速度超100 tokens/秒,适合低延迟场景。用户反馈称,GLM-4.5在Z.ai平台或智谱清言的在线体验流畅,支持聊天、制品生成和全栈开发等多种功能。本地部署方面,官方GitHub提供了vLLM和SGLang框架的详细教程,降低技术门槛。
2. 生态与开发者支持
GLM-4.5通过开源和兼容性设计吸引了大量开发者。用户可在Z.ai平台通过API调用,或在Hugging Face下载模型权重进行本地部署。实测中,开发者在Cursor、Trae等IDE中调用GLM-4.5的API,配置简单,运行稳定。此外,智谱公开了52项测试任务的数据集和智能体轨迹,便于行业验证和复现,进一步提升了模型的透明度和可信度。
用户评价中,GLM-4.5被戏称为“Gemini Little Model”,因其在文本改写、解读和翻译等任务中表现出50-60%的Gemini舒适感,稳定性优于部分竞品(如DeepSeek)。开发者尤其赞赏其在中文任务和多轮推理中的表现,认为其是中文Agent应用场景最具潜力的开源模型之一。
国产大模型的意义
GLM-4.5的发布标志着国产大模型在智能体领域的重大突破。其高效的MoE架构和原生智能体能力填补了国内模型在复杂任务处理上的空白。相比国际领先模型(如Claude-4-Sonnet、GPT-4-Turbo),GLM-4.5在中文任务、多轮推理和工具调用方面展现出显著优势,同时以低成本和高兼容性降低了企业部署门槛。
开源策略进一步推动了国产AI生态的繁荣。MIT协议的采用和Hugging Face平台的开放,使GLM-4.5成为开发者创新的基石。智谱通过提供完整API、在线体验平台和详细部署教程,构建了一个从技术研发到实际应用的闭环生态,为中小企业和个人开发者提供了“用得起、用得好”的AI基础设施。
不足与展望
尽管GLM-4.5在开源模型中表现突出,但与国际顶尖闭源模型(如Claude-4-Sonnet)相比,仍存在一定差距,尤其在复杂多模态任务和超长上下文处理能力上。用户反馈指出,模型在某些创意任务(如人物深度塑造)中尚未达到超预期效果,需进一步优化。此外,模型的多语言支持虽覆盖26种语言,但在非中英文场景下的表现仍有提升空间。
未来,智谱计划围绕智能体能力持续优化,增强多模态和长任务执行能力。GLM-4.5的开源和生态建设为国产AI的普惠化应用奠定了基础,预计将催生更多创新场景,推动AI技术成为普惠生产力工具。
更多文章