DeepSeek-V3 模型深度剖析:AI 新时代的璀璨之星

在当今人工智能飞速发展的浪潮中,DeepSeek-V3 模型宛如一颗耀眼的新星,照亮了语言模型领域的前行道路。以下将深入探究其独特魅力与价值所在。
一、架构设计——智慧与高效的融合
DeepSeek-V3 所采用的多头潜在注意力(MLA)和 DeepSeekMoE 架构无疑是其强大性能的基石。这种创新性的架构设计,通过巧妙的负载平衡策略,能够根据输入文本的具体情境灵活地激活相应的专家模块。这一过程就像是一位经验丰富的专家,面对不同的问题能够迅速调用最擅长的知识领域来解答,仅需调动 370 亿参数,却展现出超越传统模型的能力,极大地提升了计算效率和推理速度。在实际应用中,无论是复杂的文本生成任务,还是需要精准理解与回答的问答场景,都能够快速且准确地给出高质量的结果,为用户带来流畅且高效的体验,充分展现了其架构设计的精妙之处,堪称智慧与高效完美融合的典范。
二、训练过程——精心雕琢的成长之路
- 数据基石:其预训练所使用的 14.8 万亿个高质量 tokens 犹如一座知识的宝库,广泛涵盖了各个领域的丰富信息。这些数据就像是为模型提供了全面且均衡的营养,使其能够在语言理解和生成的各个方面都打下坚实的基础,从而在面对多样化的任务时都能展现出深厚的知识储备和广泛的适用性。
- 框架支撑:基于内部精心打造的 HAI-LLM 框架,通过 16 路流水线并行、64 路专家并行以及 ZeRO-1 数据并行等先进技术,结合 DualPipe 算法等一系列优化手段,为模型的训练搭建了一条高速通道。这使得模型在训练过程中能够充分利用计算资源,高效地吸收和整合知识,快速提升自身能力,确保每一次参数的更新都朝着更优的方向发展,如同一位在专业教练指导下的运动员,稳步提升自己的竞技水平。
- 技巧打磨:创新性的 FP8 混合精度训练框架以及细粒度量化策略等技术的运用,更是如同为模型训练过程中的每一个环节都进行了精心打磨。这些技术不仅降低了 GPU 内存的使用压力,使得训练过程更加稳定和高效,而且在训练成本上实现了大幅优化。在长期的训练过程中,没有出现令人困扰的损失峰值或回滚现象,确保了模型能够持续、稳定地向着更高的性能水平迈进,展现出了卓越的训练稳定性和可持续发展性。
三、创新技术——突破传统的利刃
- 多令牌预测(MTP):MTP 训练目标的设立无疑是 DeepSeek-V3 手中的一把利刃,它打破了传统训练模式的束缚。通过多个模块顺序预测额外令牌,并且完整地保持因果链,这一创新举措极大地增强了模型对文本的理解和生成能力。在实际应用中,无论是撰写逻辑严密的学术论文,还是生成富有创意和连贯性的故事,MTP 技术都能够让模型的输出更加流畅、自然且富有逻辑性,为用户提供更加优质、连贯的文本内容,展现出超越传统模型的语言驾驭能力。
- 监督微调与强化学习:经过监督微调和强化学习这两个关键阶段的精心打磨,DeepSeek-V3 充分挖掘了自身的潜力,实现了从“初出茅庐”到“独当一面”的华丽转身。监督微调阶段所使用的涵盖多个领域的数据集,如同为模型提供了丰富多样的实践场景,使其能够学习到针对不同领域问题的精准回答策略。而强化学习阶段采用的规则和模型 - 基于奖励模型及组相对策略优化,则像是为模型配备了一位严格且智慧的导师,不断引导模型在与用户的交互中优化自己的回答策略,提升回答的准确性、合理性和满意度,从而在各种复杂的实际应用场景中都能够表现出色,为用户提供更加智能、贴心的服务体验。
四、性能表现——实力铸就的辉煌成就
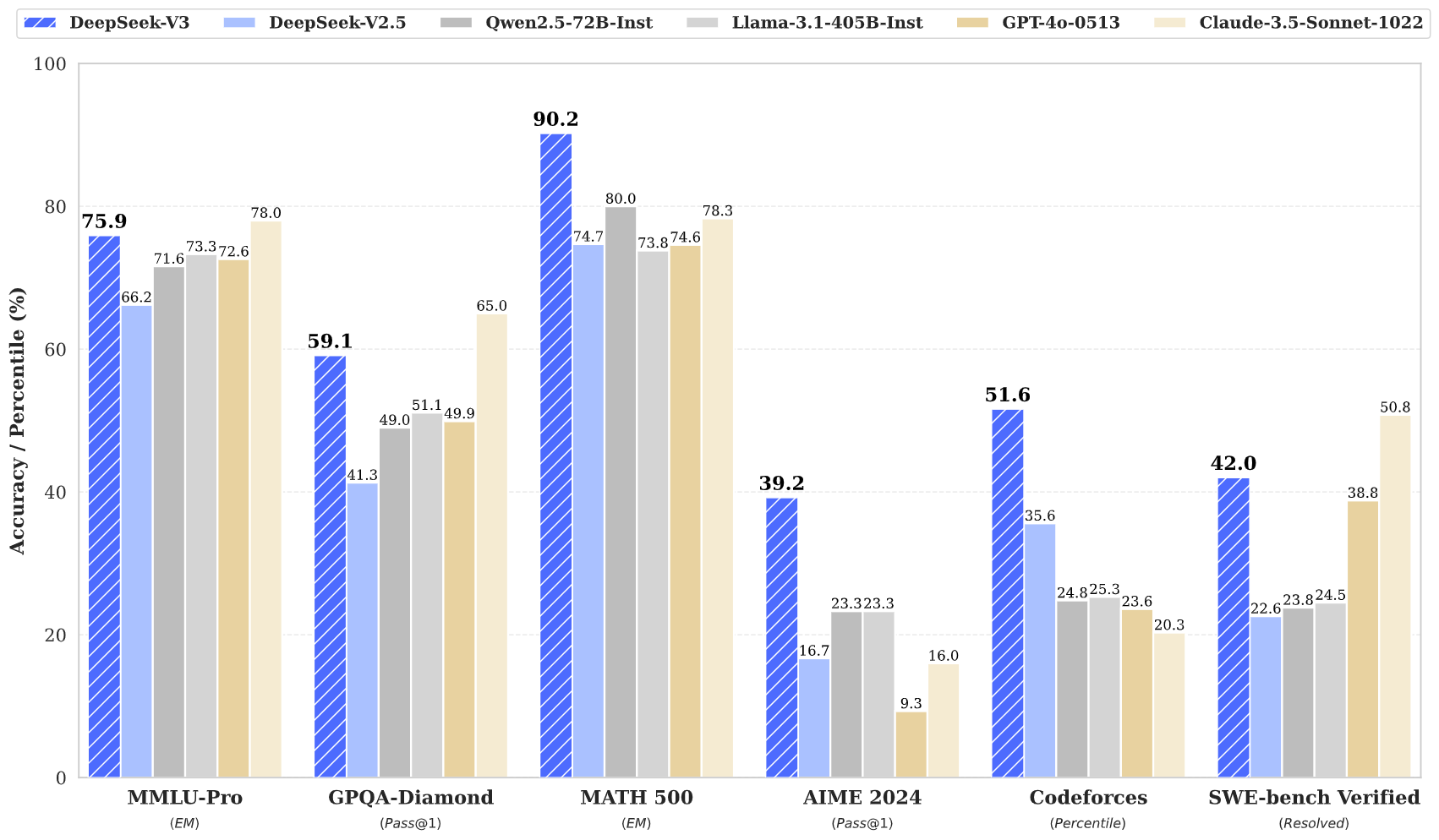
- 预训练评估:在与众多开源模型的激烈竞争中,DeepSeek-V3 在多个基准测试中脱颖而出,展现出了卓越的实力。特别是在数学和代码任务等领域,其在 Math500、AIME2024 和 Codeforces 等测试中的优异表现,充分证明了其强大的逻辑推理和编程思维能力。这使得它在处理与数学计算、编程相关的实际任务时,能够为用户提供准确、高效的解决方案,无论是解决复杂的数学难题,还是编写高质量的代码片段,都能够得心应手,为相关领域的专业人士和学习者提供了有力的支持工具。
- 后训练评估:其聊天版本在多种标准和开放 - 端基准测试中的出色表现,更是令人瞩目。不仅在与其他开源模型的较量中占据上风,而且在与 GPT-4o 和 Claude-3.5-Sonnet 等闭源模型的对比中也毫不逊色,尤其在中文事实知识等方面展现出了独特的优势。这意味着在日常的聊天交互、知识问答等场景中,DeepSeek-V3 能够为用户提供准确、详实且符合中文语言习惯和文化背景的回答,极大地提升了用户在获取信息和交流互动过程中的体验,无论是解答专业知识问题,还是进行日常的闲聊对话,都能够满足用户的需求,成为用户可靠的智能伙伴。
五、成本效益——高性价比的明智之选
在追求卓越性能的同时,DeepSeek-V3 并没有忽视成本效益这一关键因素。其训练成本仅为 2.788m H800 GPU 小时,花费 557.6 万美元,相较于 Llama3-405B 等模型的高昂训练成本,无疑具有极大的优势。这使得更多的研究机构和企业能够在有限的预算下采用这一先进的模型,推动人工智能技术在更广泛的领域得到应用和发展。而且,其 API 价格也极具吸引力,输入价格仅为 GPT-4o 的 1/20,输出价格仅为其 1/30。这对于广大开发者和企业用户来说,意味着在使用 DeepSeek-V3 进行应用开发和实际部署时,能够以更低的成本获得高质量的语言模型服务,从而在市场竞争中占据更有利的地位,无论是开发智能客服系统、内容生成平台,还是进行智能写作辅助等应用,都能够在保证性能的前提下降低运营成本,实现经济效益的最大化,是一款真正高性价比的明智之选。DeepSeek-V3 模型凭借其在架构设计、训练过程、创新技术、性能表现以及成本效益等多个方面的卓越优势,成为了当前语言模型领域的杰出代表。它不仅为人工智能技术的发展注入了新的活力,也为广大用户和开发者带来了更加智能、高效、经济的解决方案,在推动人工智能技术普及和应用的道路上迈出了坚实而有力的一步,有望在未来的智能时代中发挥更加重要的作用,引领语言模型技术走向新的辉煌。
相关地址
更多文章