CogAgent-9B重磅发布:智谱AI与清华联合研发的GUI智能交互模型 | 9B参数实现业界领先性能

智谱AI+清华大学知识工程实验室近日宣布开源其最新研究成果 CogAgent-9B,这是一个专注于图形用户界面(GUI)理解与交互的多模态智能体系统。在当今数字化时代,人们渴望智能助手能高效处理在线订票、文件管理、网页搜索等基于 GUI 的任务,但传统大型语言模型在这方面却显得力不从心。CogAgent-9B 的发布,为解决这一难题带来了新的突破。
创新架构设计
CogAgent-9B 最引人注目的技术创新在于其独特的高分辨率交叉模块设计。该模型采用仅 0.30B 参数的轻量级预训练视觉编码器,配合小隐藏尺寸的交叉注意力机制,巧妙解决了处理高分辨率 GUI 图像时的计算成本问题。这一设计使得模型能够高效处理从 224×224 到 1120×1120 像素的动态分辨率图像,在保持高性能的同时显著降低了计算开销。
在基础架构上,CogAgent-9B 以预训练的视觉语言模型为基石,采用 EVA2-CLIPE 作为低分辨率图像编码器,通过 MLP 适配器实现与视觉-语言解码器的无缝对接。其解码器融合了视觉专家模块,能够深度整合视觉和语言特征,实现高效的信息处理。
执行过程
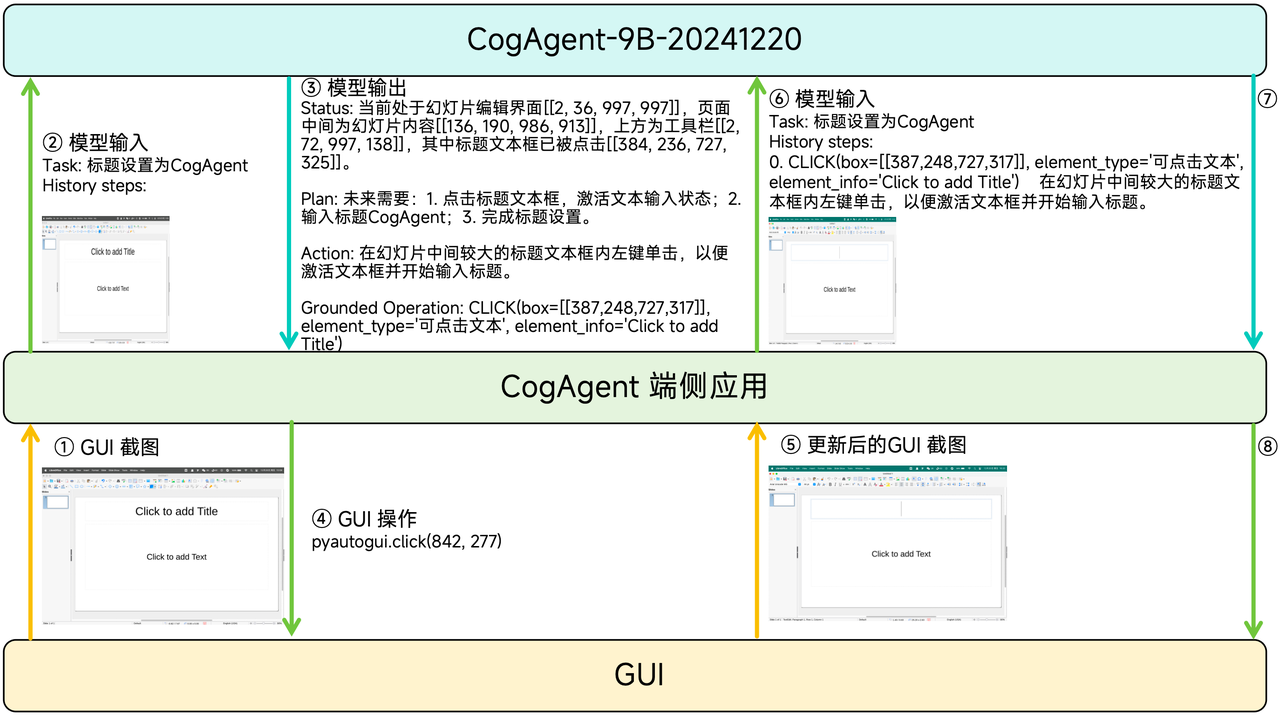
CogAgent 以 GUI 截图为唯一环境输入,结合已完成的动作历史,计算当前 GUI 截图中最合适的动作。该动作通过 CogAgent 端侧应用(如 GLM-PC 和 CogAgent Demo App)注入 GUI,GUI 响应并更新图像内容;同时,该动作被添加至动作历史。CogAgent 根据更新后的历史动作和截图,计算后续操作。此过程循环往复,直至 CogAgent 判定指令执行完毕。
突破性的训练策略
研究团队在训练数据的构建上投入了大量心血。预训练数据涵盖了三个关键领域:
- 文本识别数据:包含 80M 合成渲染文本、18M 自然图像 OCR 数据和 9M 学术文档数据
- 视觉定位数据:利用 LAION-115M 采样的 40M 图像-字幕对
- GUI 专项数据:自建的 CCS400K 数据集,包含 400,000 个网页截图和 140M 问答对
训练过程采用了创新的多阶段策略,首先冻结大部分参数,仅训练高分辨率交叉模块,随后逐步解冻其他组件。特别值得一提的是采用了课程学习方法,从简单的文本识别任务逐步过渡到更具挑战性的定位和网页数据处理。
卓越的性能表现
在实际评测中,CogAgent-9B 展现出令人瞩目的性能。在 MM-Vet 数据集上取得了 52.8 的高分,领先第二名 LLaVA-1.5 达 16.5 分;在 POPE 对抗性评估中也获得了 85.9 的优异成绩。特别是在 GUI 相关任务上,CogAgent-9B 在 Mind2Web 数据集的跨网站、跨领域和跨任务测试中,分别超越了参数量是其 4 倍的 LLaMA2-70B 达 11.6%、4.7% 和 6.6%。
广泛的应用前景
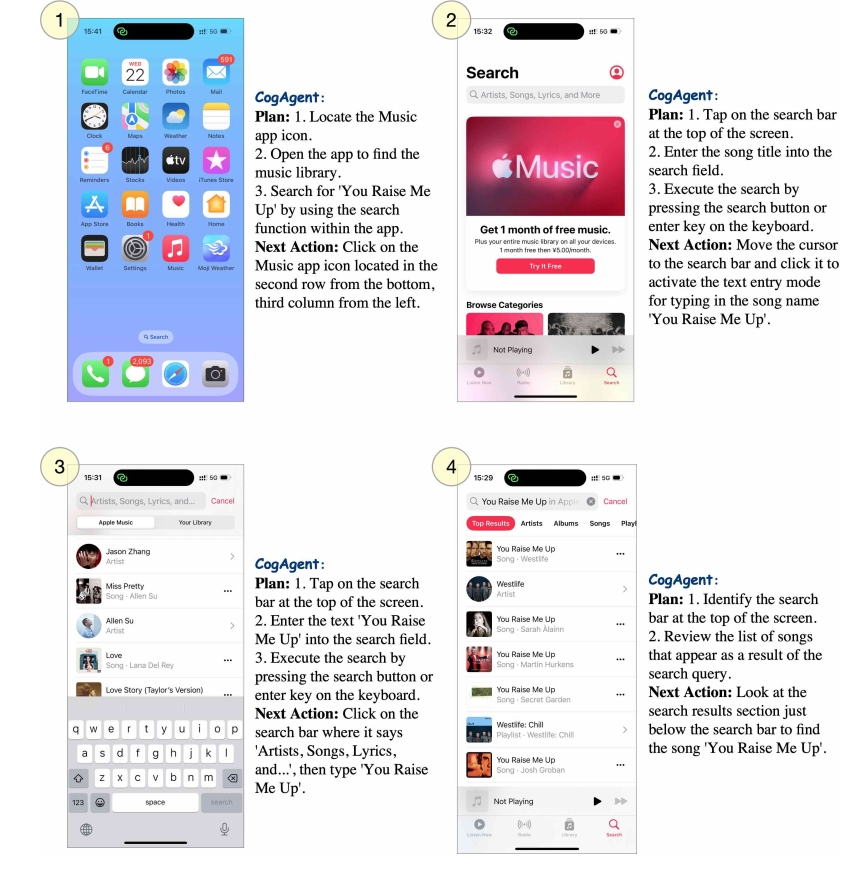
CogAgent-9B 的应用场景十分广泛。
- 在智能助手领域,它能够实现 GUI 自动化操作和视觉引导任务执行;
- 在人机交互方面,可以提升界面可访问性并优化操作流程;
- 在开发领域,则可用于 UI 测试自动化和界面设计分析。
开源与未来展望
THUKEG 团队已将 CogAgent-9B 完整开源,开发者可以通过 Hugging Face 平台获取模型权重:
展望未来,研究团队计划在多个方向继续推进:提升坐标预测精度、开发多图像输入处理能力、扩展多语言支持等。同时,团队也在积极建设开源社区,通过提供更多示例代码和完善的开发文档,促进技术的广泛应用和创新。
这一开源项目的发布,不仅为 AI 领域特别是 GUI 交互和多模态理解方向带来了新的可能性,更为智能助手的发展开辟了新的道路。随着后续研究的深入和社区的共同努力,CogAgent 有望在推动人机交互技术进步方面发挥更加重要的作用。
在线体验
本地运行
git clone https://github.com/THUDM/CogAgent.git
cd CogAgent
pip install -r requirements.txt模型下载也可以用 魔塔 下载
modelscope download --model ZhipuAI/cogagent-9b-20241220 --local_dir ./cogagent运行一个本地的基于transformers的模型推理,你可以通过运行以下命令来运行模型:
python inference/cli_demo.py --model_dir THUDM/cogagent-9b-20241220 --platform "Mac" --max_length 4096 --top_k 1 --output_image_path ./results --format_key status_action_op_sensitive这是一个命令行交互代码。你需要输入对应的图像路径。 如果模型返回的结果带有bbox,则会输出一张带有bbox的图片,表示需要在这个区域内执行操作,保存的图片为路径为 output_image_path中,图片名称为 你输入的图片名_对话轮次.png 。format_key 表示你希望通过模型通过哪种格式返回。 platform 字段则决定了你服务于哪种平台(比如Mac,则你上传的截图都必须是Mac系统的截图)。
webui Demo
python inference/web_demo.py --host 0.0.0.0 --port 7860 --model_dir THUDM/cogagent-9b-20241220 --format_key status_action_op_sensitive --platform "Mac" --output_dir ./results注意事项
- 该模型不是对话模型,不支持连续对话,请发送具体指令,并参考我们提供的历史拼接方式进行拼接。
- 该模型必须要有图片传入,纯文字对话无法实现GUI Agent任务。
- 该模型输出有严格的格式要求,请严格按照我们的要求进行解析。输出格式为 STR 格式,不支持输出JSON 格式。
相关链接
更多文章