STAR: Spatial-Temporal Augmentation with Text-to-Video Models for Real-World Video Super-Resolution

Introduction
STAR (Spatial-Temporal Augmentation with Text-to-Video Models) is an innovative real-world video super-resolution framework jointly developed by Nanjing University, ByteDance, and Southwest University. It is the first to integrate diverse, powerful text-to-video diffusion priors into real-world video super-resolution, effectively addressing various challenges faced by traditional methods in processing real-world videos.
Core Features
- 🌟 Innovative Spatio-Temporal Quality Enhancement Framework: Specifically designed for real-world video super-resolution
- 🎯 Powerful Text-to-Video Model Integration: Leveraging T2V models for video quality enhancement
- 🔄 Excellent Temporal Consistency: Effectively maintaining coherence between video frames
- 🖼️ Realistic Spatial Details: Generating high-quality, detail-rich video frames
- 🛠️ Practical Open-Source Implementation: Providing complete code and pre-trained models
Technical Principles
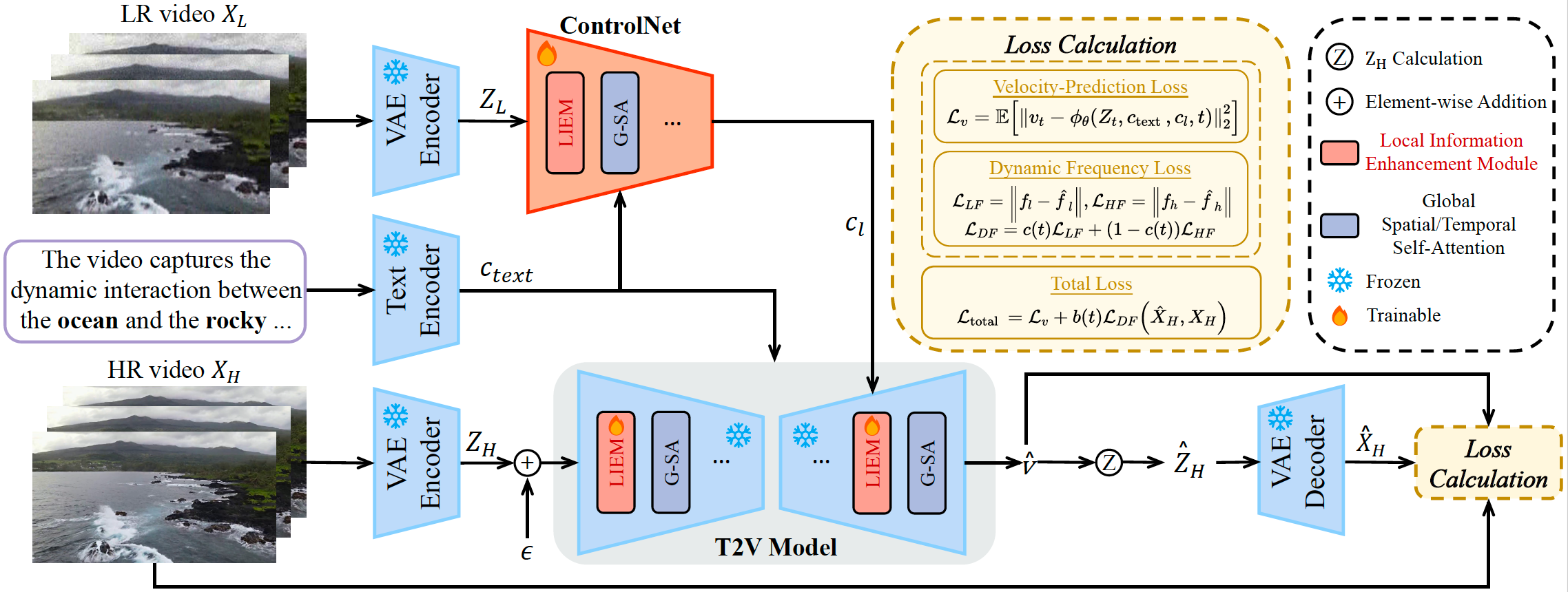
STAR framework consists of four main modules:
- VAE Encoder: Processes video input
- Text Encoder: Handles prompt text
- ControlNet: Controls the generation process
- T2V Model with Local Information Enhancement Module (LIEM):
- LIEM specifically designed to reduce artifacts
- Dynamic Frequency (DF) Loss for adaptive adjustment of high and low-frequency component constraints
These components work together to achieve high spatio-temporal quality, reduced artifacts, and enhanced fidelity.
Installation and Usage
Environment Setup
# Clone repository
git clone https://github.com/NJU-PCALab/STAR.git
cd STAR
# Create environment
conda create -n star python=3.10
conda activate star
pip install -r requirements.txt
sudo apt-get update && apt-get install ffmpeg libsm6 libxext6 -yPre-trained Models
STAR offers two base model versions:
-
I2VGen-XL Based Version
- Light Degradation Model: Suitable for videos with minor quality loss
- Heavy Degradation Model: Suitable for videos with severe quality loss
-
CogVideoX-5B Based Version
- Specifically for processing heavily degraded videos
- Only supports 720x480 input resolution
Usage Steps
-
Download Pre-trained Models
- Download model weights from HuggingFace
- Place weight files in the
pretrained_weight/directory
-
Prepare Test Data
- Place test videos in the
input/video/directory - Text prompts have three options:
- No prompt
- Automatically generate prompts using Pllava
- Manually write prompts (place in
input/text/)
- Place test videos in the
-
Configure Paths Modify paths in
video_super_resolution/scripts/inference_sr.sh:- video_folder_path
- txt_file_path
- model_path
- save_dir
-
Run Inference
bash video_super_resolution/scripts/inference_sr.shNote: If encountering memory issues, you can set a smaller
frame_lengthvalue ininference_sr.sh.
Practical Effects
STAR demonstrates significant advantages in processing real-world videos:
- Effectively enhances quality of low-resolution videos from platforms like Bilibili
- Significantly improves visual quality when processing heavily degraded videos
- Maintains good temporal coherence in generated videos
- High detail fidelity without over-smoothing effects
Summary
STAR provides a powerful solution for real-world video super-resolution. Through innovative architectural design and integration of advanced text-to-video models, it effectively handles video quality enhancement needs in various real-world scenarios. The project’s open-source nature also enables researchers and developers to conveniently use and improve this technology.
More Articles
![OpenAI 12-Day Technical Livestream Highlights Detailed Report [December 2024]](/_astro/openai-12day.C2KzT-7l_1ndTgg.jpg)







