Breaking: OpenAI Launches o3 All-Purpose Inference Model and Efficient o4-mini
Key Points
OpenAI released the o3 and o4-mini models on April 16, 2025, potentially representing the most advanced inference models to date, supporting visual reasoning and tool use.
Research shows that o3 excels in coding, mathematics, science, and visual tasks, while o4-mini is optimized for fast, cost-effective inference tasks.
Evidence indicates significant improvements in both safety and performance, including reduced critical errors and enhanced safety rejection prompts.
Model Features and Capabilities
OpenAI’s o3 and o4-mini models are designed to handle complex problems, equipped with tools such as web search, Python analysis, and image generation. o3 particularly excels in coding, mathematics, science, and visual tasks, while o4-mini is optimized for high-throughput tasks, offering fast and economical solutions. Both models can reference past conversations to provide more personalized interactions.
For example, o3 performs exceptionally well in handling complex queries, while o4-mini is suited for scenarios requiring quick responses due to its efficiency. These capabilities are enhanced through tool usage, such as obtaining real-time information via web search or processing data through Python analysis.
Performance Improvements
Compared to the previous o1 model, o3 has reduced major errors by 20%, showing particular excellence in programming, business, and creative ideation. o4-mini surpasses o3-mini in non-STEM tasks and data science, with higher usage limits due to its efficiency. These improvements make the models more attractive for applications requiring high accuracy and efficiency.
Additionally, both models show significant improvements in instruction following and conversation naturalness, better understanding user intent and providing more natural interaction experiences. For instance, they can reference previous conversation content to provide more personalized responses.
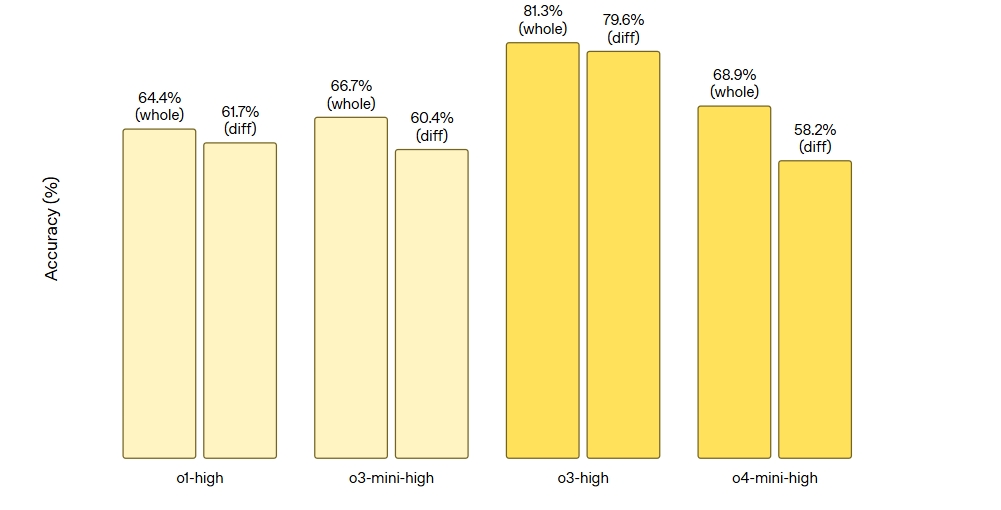
Benchmark Results
To evaluate these new models’ performance, OpenAI provided detailed comparisons across multiple benchmarks, covering mathematics, science, coding, and visual reasoning domains. Here are the key benchmark results:
| Model | AIME 2024 | AIME 2025 | Codeforces ELO | GPQA Diamond | MMMU | MathVista | CharXiv-Reasoning | SWE-Bench | Deep Research |
|---|---|---|---|---|---|---|---|---|---|
o1 | 74.3 | 79.2 | 1891 | 78.0 | 77.6 | 71.8 | 55.1 | 48.9 | 8.12 |
o3-mini | 87.3 | 86.5 | 2073 | 77.0 | - | - | - | 49.3 | 13.40 |
o3 (no tools) | 91.6 | 88.9 | 2706 | 83.3 | 82.9 | 86.8 | 78.6 | 69.1 | 20.32/24.90* |
o4-mini (no tools) | 93.4 | 92.7 | 2719 | 81.4 | 81.6 | 84.3 | 72.0 | 68.1 | 14.28/17.70* |
These benchmarks include:
AIME: American Invitational Mathematics Examination, testing advanced mathematical abilities, witho4-miniachieving 93.4% and 92.7% accuracy in 2024 and 2025 respectively.GPQA: General Problem Question Answering, focusing on diamond-level doctoral science questions, witho3scoring 83.3% ando4-miniscoring 81.4% without tools.MMMU: College-level visual problem solving, witho3ando4-miniscoring 82.9% and 81.6% respectively.MathVista: Visual mathematical reasoning, witho3scoring 86.8% ando4-miniscoring 84.3%.CharXiv-Reasoning: Scientific graph reasoning, witho3scoring 78.6% ando4-miniscoring 72.0%.SWE-Bench: Verified software engineering tasks, witho3scoring 69.1% ando4-miniscoring 68.1%.Deep Research: Cross-disciplinary expert-level questions, witho3scoring 24.9% ando4-miniscoring 17.7% with tools.
Cost and Performance
o3 offers performance improvements over o1, while o4-mini is smarter and more cost-effective compared to o3-mini, particularly in AIME and GPQA evaluations. This makes them more attractive for real-world applications, balancing performance and cost.
Safety Measures
Safety is OpenAI’s top priority. The new models include new rejection prompts for bio-risks, malware, and jailbreaking to prevent harmful or dangerous content generation. The inference LLM monitor successfully flagged approximately 99% of dangerous conversations in human red team testing. According to OpenAI’s preparedness framework, these models score below the “high” threshold in categories of biological and chemical risks, cybersecurity, and AI self-improvement. Detailed safety results can be found in the system cards.
New Features
In addition to the new models, OpenAI has launched Codex CLI, a lightweight terminal coding agent that maximizes the inference capabilities of o3 and o4-mini, with planned support for the upcoming GPT-4.1. Codex CLI supports multimodal reasoning through screenshots or low-fidelity sketches and accesses local code, serving as a versatile tool for developers. It’s fully open-source and available on GitHub.
Access and Availability
o3 and o4-mini are now available to ChatGPT Plus, Pro, and Team users, replacing the o1, o3-mini, and o3-mini-high models. Enterprise users will gain access within a week, while free users can experience o4-mini through the “Think” feature in the composer. For developers, API access is provided through chat completions and response APIs, with documentation available in the OpenAI API documentation.
More Articles
![OpenAI 12-Day Technical Livestream Highlights Detailed Report [December 2024]](/_astro/openai-12day.C2KzT-7l_1ndTgg.jpg)







