How Did Kimi K2 Achieve a Trillion-Parameter Open Model with Three Major Innovations?

Moonshot AI recently released the Kimi K2 technical report, revealing the birth details of a trillion-parameter open-source model. Unlike a product launch, this 32-page technical document provides us with a window into the core technologies behind cutting-edge AI models. The report details how Kimi K2 innovates in training stability, data efficiency, and model architecture, ultimately achieving SOTA (State-of-the-art) performance on multiple key benchmarks.
This article will deeply interpret the report for you, analyzing the three technological pillars supporting Kimi K2’s strong performance.
Pillar One: MuonClip Optimizer—The “Super Stabilizer” for Trillion-Parameter Model Training
Training ultra-large language models is like piloting a high-performance experimental aircraft—any slight disturbance can lead to catastrophic “training collapse” (i.e., “loss spikes”). The Kimi team pointed out in the report that to pursue higher training efficiency (i.e., “token efficiency”), they adopted the Muon optimizer, but found that this optimizer is more prone to “attention logits explosion” when scaling up, leading to training instability.
To solve this global problem, the team proposed an innovative optimizer called MuonClip. Its core is a new technology called QK-Clip, which works as a precise “per-head adaptive regulator”:
- Monitoring and Intervention: QK-Clip monitors the internal computation values (logits) of each attention head in real time.
- Precise Adjustment: Once a head’s value exceeds the preset safety threshold
τ, it immediately activates and scales only this “abnormal” head, without affecting other normal heads. - Automatic Deactivation: When training stabilizes and all heads’ values return to normal, QK-Clip automatically “sleeps” and stops intervening, achieving minimal intervention.
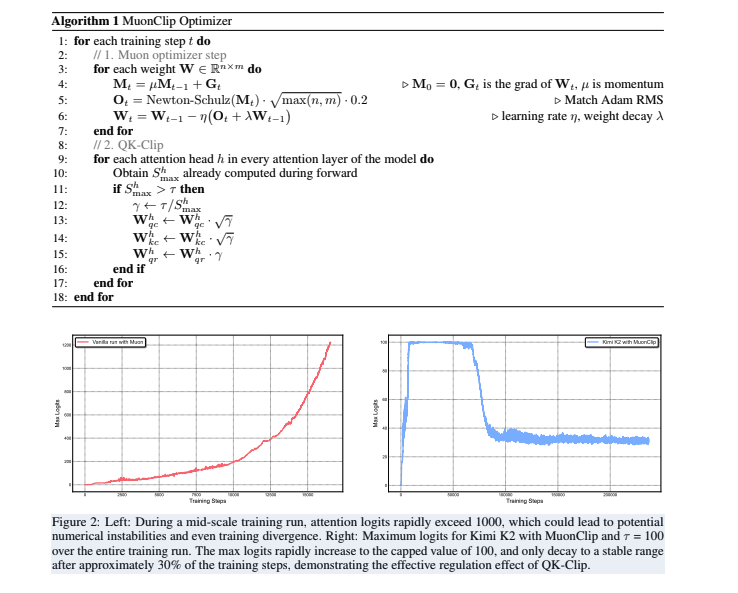
Figure: Left shows training without the stabilizer, where attention logits spike rapidly; right shows Kimi K2 with MuonClip, where logits are effectively controlled below the threshold of 100 and stabilize later.
The report emphasizes that during the entire 15.5 trillion training tokens, Kimi K2 did not experience a single loss spike. This result proves MuonClip’s outstanding effect in ensuring large-scale model training stability, providing valuable engineering experience for the industry to explore even larger models.
Pillar Two: The Art of Data Reuse—From “Repetitive Feeding” to “Knowledge Rephrasing”
As high-quality data increasingly becomes a bottleneck, how to extract more value from limited data is a core issue for all AI companies. Simple multi-epoch training of the same data not only yields diminishing returns but also leads to overfitting and loss of generalization.
To address this, the Kimi K2 team designed a sophisticated data rephrasing process to improve “token utility,” i.e., the effective contribution of each token to model training.
The report details rephrasing strategies for two major domains:
- Knowledge Data: By carefully designed prompts, a powerful auxiliary LLM is guided to rewrite the original text from different styles and perspectives. For long documents, “chunked autoregressive generation” is used to ensure no loss of global information.
- Mathematical Data: Inspired by SwallowMath, high-quality math documents are rephrased into “study notes” style to enhance the model’s reasoning ability.
Experimental data strongly proves the effectiveness of this strategy. In SimpleQA accuracy tests, using data rephrased 10 times and trained for 1 epoch, the model achieved 28.94% accuracy, significantly higher than the 23.76% from training the original data for 10 epochs. This shows that high-quality rephrasing enables the model to absorb knowledge more deeply, rather than mechanically memorizing.
Pillar Three: Highly Sparse MoE Architecture—Balancing Trillion Parameters and Inference Efficiency
Kimi K2 is based on a Mixture-of-Experts (MoE) model with 1.04 trillion total parameters, but only 32.6 billion are activated per forward pass. The MoE architecture allows the model to have huge knowledge capacity while maintaining relatively low inference cost through “sparse activation.”
The Kimi team found through its “Sparsity Scaling Law” research that, with fixed activated parameters, increasing the total number of experts (i.e., increasing sparsity) continuously reduces validation loss and improves performance. Kimi K2 chose a sparsity of 48 (activating 8 out of 384 experts), balancing performance and cost.
In the report, the comparison between Kimi K2 and DeepSeek-V3 architectures clearly reveals its unique design trade-offs:
| Architecture Parameter | DeepSeek-V3 | Kimi K2 | Change | Technical Consideration |
|---|---|---|---|---|
| Total Parameters | 671B | 1.04T | ▲ 54% | According to scaling law, increasing total parameters raises the model’s performance ceiling. |
| Total Experts | 256 | 384 | ▲ 50% | Increasing sparsity is key to improving MoE model performance. |
| Activated Parameters | 37B | 32.6B | ▼ 13% | Further reduces per-inference computation while ensuring performance. |
| Attention Heads | 128 | 64 | ▼ 50% | Significantly reduces inference cost and memory usage in long-context scenarios, which is crucial for agent tasks requiring complex context handling. |
This combination of “increasing model depth (more experts)” and “reducing inference width (fewer attention heads)” enables Kimi K2 to find a sweet spot between theoretical performance and practical efficiency, especially strengthening its potential in future core scenarios—long-context processing and Agentic AI.
Conclusion
The Kimi K2 technical report is not just a showcase of achievements, but a valuable sharing of technical routes. Through the innovative MuonClip optimizer, it solves the stability problem of ultra-large model training; through data rephrasing strategies, it improves data utilization efficiency; and through a carefully designed MoE architecture, it achieves a delicate balance between model performance and inference cost. These technical details together form the cornerstone of Kimi K2’s powerful capabilities and provide highly valuable references for the open-source community to explore the future of AGI (Artificial General Intelligence).
Technical Report Download
More Articles
![OpenAI 12-Day Technical Livestream Highlights Detailed Report [December 2024]](/_astro/openai-12day.C2KzT-7l_1ndTgg.jpg)







