DeepSeek R1:How Reinforcement Learning Reshapes Language Model Reasoning?
Recently, the AI field has welcomed another groundbreaking research achievement - DeepSeek R1. This reasoning model has achieved significant breakthroughs in performance, even rivaling OpenAI’s o1-1217. Its emergence not only opens up new paths for the development of Large Language Models (LLMs) but also injects new vitality into the entire AI research field. Today, let’s delve into the research paper behind DeepSeek R1 and explore its innovations and strengths.
DeepSeek R1: Challenges and Breakthroughs
In the wave of AI development, LLMs are rapidly iterating, continuously narrowing the gap with Artificial General Intelligence (AGI). Post-training, as a key component of the training process, can effectively improve model accuracy in reasoning tasks and better align models with social values and user preferences. Previously, OpenAI’s o1 series models made significant progress in reasoning tasks by increasing the length of chain-of-thought reasoning processes, but how to achieve effective test-time scaling remains a pressing challenge for academia.
Against this backdrop, the DeepSeek R1 research team took a different approach, attempting to use pure reinforcement learning (RL) to enhance language models’ reasoning capabilities. Their goal was clear: to explore the potential of LLMs to evolve reasoning capabilities through pure RL processes without any supervised data.
Using DeepSeek-V3-Base as the foundation model and GRPO (Group Relative Policy Optimization) as the RL framework, the research team made an exciting discovery: DeepSeek R1-Zero (a pure RL model without supervised fine-tuning) demonstrated powerful and interesting reasoning behaviors. After thousands of RL training steps, DeepSeek R1-Zero’s performance in reasoning benchmarks improved significantly. For example, in the AIME 2024 test, its single-sample pass rate (pass@1) soared from 15.6% to 71.0%; with majority voting strategy, this score could increase to 86.7%, comparable to OpenAI-o1-0912’s level.
However, DeepSeek R1-Zero wasn’t perfect, facing issues like poor readability and language mixing. To address these problems and further improve reasoning performance, the research team introduced DeepSeek R1. Through incorporating a small amount of cold-start data and multi-stage training process, DeepSeek R1 successfully overcame some of DeepSeek R1-Zero’s shortcomings, ultimately achieving performance comparable to OpenAI-o1-1217.
Technical Highlights: Innovative Architecture and Training Strategy
DeepSeek R1-Zero: Deep Exploration of Reinforcement Learning
The training process of DeepSeek R1-Zero is unique. The team adopted the GRPO algorithm, which abandons the critic model of the same size as the policy model and estimates baselines through group scores, significantly reducing training costs.
In reward modeling, the team implemented a rule-based reward system, primarily including accuracy rewards and format rewards. Accuracy rewards evaluate whether the model’s answers are correct, such as requiring models to provide final answers in specified formats for mathematical problems to verify correctness; format rewards require models to place thinking processes between "
To guide model training, the team designed a concise template. This template requires the model to first reason and then provide final answers, while avoiding specific content restrictions to observe the model’s natural development during the RL process.
During training, DeepSeek R1-Zero demonstrated remarkable self-evolution capabilities. As training steps increased, its accuracy in the AIME 2024 test steadily improved. Moreover, the model learned self-reflection and exploration of multiple problem-solving methods. When encountering complex problems, it would reassess previous steps and try different solving approaches, demonstrating the charm of reinforcement learning by autonomously developing advanced problem-solving strategies.
DeepSeek R1: Optimized Upgrade with Cold-Start Data
DeepSeek R1’s training process consists of four stages, aimed at addressing DeepSeek R1-Zero’s issues while further improving model performance.
In the cold-start phase, the team constructed and collected a small amount of high-quality long Chain-of-Thought (CoT) data to fine-tune the DeepSeek-V3-Base model as the initial actor for RL training. This cold-start data was carefully designed with good readability to effectively avoid model instability in the early training stages.
During the reasoning-oriented reinforcement learning phase, the team employed the same large-scale RL training process as DeepSeek R1-Zero but introduced language consistency rewards to mitigate language mixing issues in thought chains. Although this reward mechanism slightly decreased model performance, it made the model’s output more aligned with human reading habits.
As reasoning-oriented RL training approached convergence, the team used rejection sampling and supervised fine-tuning (SFT) to collect more data. They collected data not only from reasoning tasks but also from other domains like writing and role-playing to enhance the model’s general capabilities. During this process, the team strictly filtered the data, removing content with language mixing, lengthy paragraphs, and code blocks that were difficult to read.
To better align with human preferences, the team conducted full-scenario reinforcement learning. In this stage, they combined various reward signals and diverse prompt distributions for further training. For reasoning data, they continued using rule-based rewards; for general data, they employed reward models to capture human preferences. This approach ensured the model maintained reasoning capabilities while focusing more on user helpfulness and harmlessness.
Model Distillation: Empowering Small Models with Strong Reasoning Capabilities
To equip more efficient small models with powerful reasoning capabilities, the research team distilled knowledge from DeepSeek R1 to smaller models. They directly fine-tuned open-source models like Qwen and Llama using 800k samples generated by DeepSeek R1. The experimental results were impressive, with distilled small models showing significant improvements in reasoning capabilities. For example, DeepSeek-R1-Distill-Qwen-7B achieved a score of 55.5% in the AIME 2024 test, surpassing QwQ-32B-Preview; DeepSeek-R1-Distill-Qwen-32B performed excellently in multiple tests, comparable to o1-mini. These results demonstrate that distilling large models’ reasoning patterns into smaller models is a highly effective method, enabling small models to maintain efficiency while gaining powerful reasoning capabilities.
Experimental Results: Comprehensive Excellence and Leadership
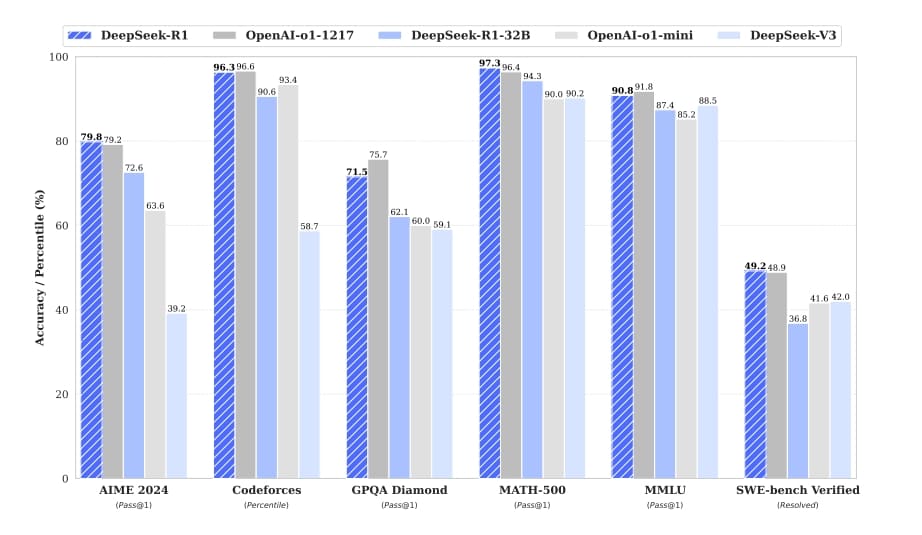
The research team conducted extensive experimental evaluations of DeepSeek R1 and its distilled smaller models, covering multiple benchmarks including MMLU, MMLU-Pro, GPQA Diamond, AIME 2024, LiveCodeBench, and comparing them with several powerful baseline models.
In education-oriented knowledge benchmarks, DeepSeek R1 outperformed DeepSeek-V3, particularly in STEM-related questions, achieving significant accuracy improvements through large-scale RL training. In tasks with long context dependencies like FRAMES, DeepSeek R1 also demonstrated powerful document analysis capabilities.
In mathematical tasks and coding algorithm tasks, DeepSeek R1’s performance matched OpenAI-o1-1217, significantly surpassing other models. In writing tasks and open-domain question answering, DeepSeek R1 excelled in AlpacaEval 2.0 and ArenaHard tests, generating concise summaries while avoiding length bias, further proving its robustness in multi-task processing.
The distilled smaller models also performed excellently, with DeepSeek-R1-Distill-Qwen-7B surpassing non-reasoning models like GPT-4o-0513 in the AIME 2024 test; DeepSeek-R1-Distill-Qwen-14B exceeded QwQ-32B-Preview in all evaluation metrics; DeepSeek-R1-Distill-Qwen-32B and DeepSeek-R1-Distill-Llama-70B significantly outperformed o1-mini in most benchmarks. These results fully demonstrate the effectiveness of distillation technology and DeepSeek R1’s powerful reasoning and generalization capabilities.
Future Prospects: Continuous Innovation and Expansion
The emergence of DeepSeek R1 undoubtedly brings new ideas and methods to LLM development, but the research team isn’t satisfied with just this. In their paper, they pointed out future research directions aimed at further improving DeepSeek R1’s performance and application scope.
In terms of general capabilities, DeepSeek R1 still has room for improvement in tasks like function calling, multi-turn dialogue, complex role-playing, and JSON output. The team plans to explore how to use long thought chains to optimize the handling of these tasks.
Regarding language mixing issues, DeepSeek R1 is currently optimized mainly for Chinese and English, and may experience language mixing when handling queries in other languages. In the future, the team will work on resolving this issue to better handle tasks in multiple languages.
In prompt engineering, DeepSeek R1 is relatively sensitive to prompts, with few-shot prompts leading to performance degradation. The team recommends users adopt zero-shot settings to describe problems and specify output formats for best results. In the future, they will further research how to optimize the model’s adaptability to prompts and improve model stability under different prompt conditions.
In software engineering tasks, DeepSeek R1’s improvement was limited due to long evaluation times affecting RL process efficiency. Future versions will improve efficiency through rejection sampling of software engineering data or introducing asynchronous evaluation in the RL process, thereby enhancing model performance in software engineering tasks.
DeepSeek R1’s research findings provide important reference and inspiration for improving LLMs’ reasoning capabilities, with its innovative training methods and excellent experimental results creating high expectations for AI’s future development. Under the continuous efforts of the research team, DeepSeek R1 is expected to achieve greater breakthroughs and bring more surprises to the AI field. As AI enthusiasts, we should continue following DeepSeek R1’s development and witness the ongoing progress of AI technology.
Related Links
More Articles
![OpenAI 12-Day Technical Livestream Highlights Detailed Report [December 2024]](/_astro/openai-12day.C2KzT-7l_1ndTgg.jpg)







