CogAgent-9B Released: A GUI Interaction Model Jointly Developed by Zhipu AI and Tsinghua

Zhipu AI and the Knowledge Engineering Laboratory at Tsinghua University recently announced the open-source release of their latest research achievement, CogAgent-9B, a multimodal agent system focused on graphical user interface (GUI) understanding and interaction. In today’s digital age, people desire intelligent assistants that can efficiently handle GUI-based tasks like online booking, file management, and web searching, but traditional large language models have struggled in this aspect. The release of CogAgent-9B brings a new breakthrough in addressing this challenge.
Innovative Architecture Design
CogAgent-9B’s most notable technical innovation lies in its unique high-resolution cross-module design. The model employs a lightweight pre-trained vision encoder with only 0.30B parameters, coupled with cross-attention mechanisms using small hidden dimensions, cleverly solving the computational cost issues when processing high-resolution GUI images. This design enables the model to efficiently handle dynamic resolution images from 224×224 to 1120×1120 pixels, significantly reducing computational overhead while maintaining high performance.
In its basic architecture, CogAgent-9B builds upon pre-trained vision-language models, using EVA2-CLIPE as the low-resolution image encoder, achieving seamless integration with the vision-language decoder through MLP adapters. Its decoder incorporates visual expert modules, enabling deep integration of visual and language features for efficient information processing.
Execution Process
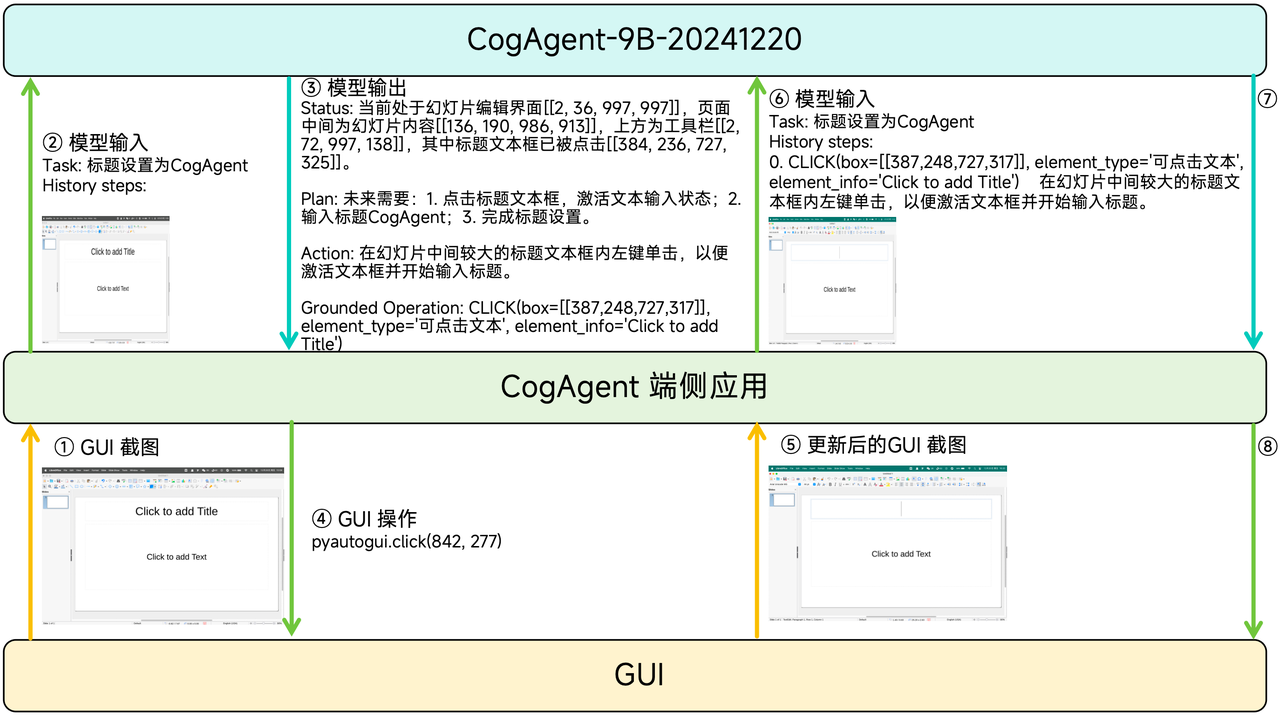
CogAgent takes GUI screenshots as the sole environmental input and combines them with completed action history to compute the most appropriate action for the current GUI screenshot. This action is injected into the GUI through CogAgent client-side applications (such as GLM-PC and CogAgent Demo App), and the GUI responds by updating the image content. Meanwhile, the action is added to the action history. CogAgent calculates subsequent operations based on the updated action history and screenshots. This process continues cyclically until CogAgent determines the instruction execution is complete.
Breakthrough Training Strategy
The research team invested significant effort in constructing training data. The pre-training data covers three key areas:
- Text Recognition Data: Including 80M synthetic rendered text, 18M natural image OCR data, and 9M academic document data
- Visual Localization Data: 40M image-caption pairs sampled from LAION-115M
- GUI-Specific Data: Self-built CCS400K dataset containing 400,000 webpage screenshots and 140M Q&A pairs
The training process adopted an innovative multi-stage strategy, initially freezing most parameters and only training the high-resolution cross module, then gradually unfreezing other components. Notably, it employed a curriculum learning approach, progressing from simple text recognition tasks to more challenging localization and webpage data processing.
Outstanding Performance
In practical evaluations, CogAgent-9B has demonstrated remarkable performance. It achieved a high score of 52.8 on the MM-Vet dataset, leading the second-place LLaVA-1.5 by 16.5 points, and scored an impressive 85.9 in the POPE adversarial evaluation. Particularly in GUI-related tasks, CogAgent-9B surpassed LLaMA2-70B (which has 4 times the parameters) by 11.6%, 4.7%, and 6.6% in cross-site, cross-domain, and cross-task tests on the Mind2Web dataset, respectively.
Broad Application Prospects
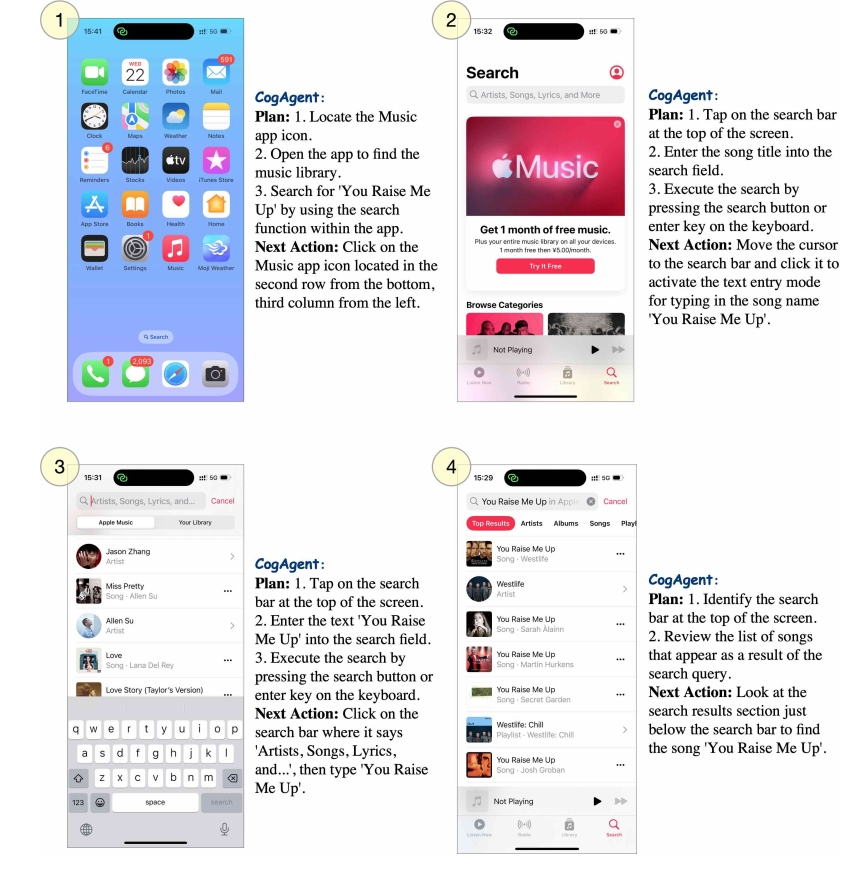
CogAgent-9B has extensive application scenarios:
- In intelligent assistance, it enables GUI automation and vision-guided task execution
- In human-computer interaction, it enhances interface accessibility and optimizes operation processes
- In development, it can be used for UI test automation and interface design analysis
Open Source and Future Outlook
The THUKEG team has fully open-sourced CogAgent-9B, with model weights available through the Hugging Face platform:
Looking ahead, the research team plans to advance in multiple directions: improving coordinate prediction accuracy, developing multi-image input processing capabilities, expanding multilingual support, and more. The team is also actively building an open-source community by providing more example code and comprehensive development documentation to promote widespread application and innovation.
The release of this open-source project not only brings new possibilities to the AI field, especially in GUI interaction and multimodal understanding but also paves new paths for the development of intelligent assistants. With continued research and community efforts, CogAgent is poised to play an increasingly important role in advancing human-computer interaction technology.
Online Experience
Local Setup
git clone https://github.com/THUDM/CogAgent.git
cd CogAgent
pip install -r requirements.txtModel Download via Modelscope
modelscope download --model ZhipuAI/cogagent-9b-20241220 --local_dir ./cogagentRun Local Transformers-based Model Inference
python inference/cli_demo.py --model_dir THUDM/cogagent-9b-20241220 --platform "Mac" --max_length 4096 --top_k 1 --output_image_path ./results --format_key status_action_op_sensitiveThis is a command-line interactive code. You need to input the corresponding image path. If the model’s result includes bbox, it will output an image with bbox indicating the area for operation. The saved image path is in output_image_path, with the image name format as your_input_image_name_dialogue_round.png. The format_key indicates your preferred model return format. The platform field determines which platform you’re serving (e.g., for Mac, all uploaded screenshots must be from Mac systems).
WebUI Demo
python inference/web_demo.py --host 0.0.0.0 --port 7860 --model_dir THUDM/cogagent-9b-20241220 --format_key status_action_op_sensitive --platform "Mac" --output_dir ./resultsImportant Notes
- This model is not a conversational model and doesn’t support continuous dialogue. Please send specific instructions and refer to our provided history concatenation method.
- The model requires image input; pure text dialogue cannot accomplish GUI Agent tasks.
- The model output has strict format requirements. Please strictly follow our requirements for parsing. The output format is STR format, and JSON format output is not supported.
Related Links
More Articles
![OpenAI 12-Day Technical Livestream Highlights Detailed Report [December 2024]](/_astro/openai-12day.C2KzT-7l_1ndTgg.jpg)